基于领域特定语言的客服机器人设计与实现
描述
领域特定语言(Domain Specific Language,DSL)可以提供一种相对简单的文法,用于特定领域的业务流程定制。本作业要求定义一个领域特定脚本语言,这个语言能够描述在线客服机器人(机器人客服是目前提升客服效率的重要技术,在银行、通信和商务等领域的复杂信息系统中有广泛的应用)的自动应答逻辑,并设计实现一个解释器解释执行这个脚本,可以根据用户的不同输入,根据脚本的逻辑设计给出相应的应答。
基本要求
脚本语言的语法可以自由定义,只要语义上满足描述客服机器人自动应答逻辑的要求。
程序输入输出形式不限,可以简化为纯命令行界面。
应该给出几种不同的脚本范例,对不同脚本范例解释器执行之后会有不同的行为表现。
实现
本程序采用rust进行实现,因为rust具有一些显著优点:
具有包管理器和配置工具cargo
内置单元测试和集成测试,而且通过cargo可以自动运行所有测试桩,不用找其他工具进行额外配置
严格的编译期管理和检查,对于每个不符合rust码风要求的地方都会warning来提醒里改善代码,使得该项目代码有着良好的风格
脚本文法介绍
符号说明
关键词:
global:用于声明全局变量
speak:用于输出机器人回答
input:用于获取用户输入
if :用于条件判断
exit:用于终止程序
loop:用于进行无限循环
标识符:以字母开头,其余可为’_',字母和数字
数字:只支持十进制整数和小数
字符串:被""包围部分
注释:"#"后一整行
语句定义规则
1 | program := globalvariable* mainloop |
解释器的实现思路
模块划分与功能实现过程
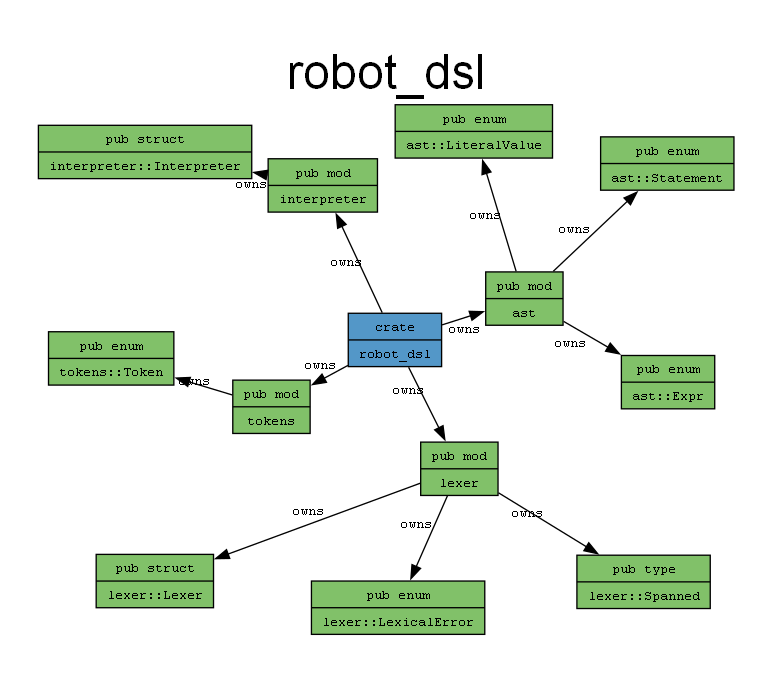
通过以下代码实现各模块之间合作:
1 | let source_code = std::fs::read_to_string(args[1].clone())?; |
由代码可知,解释器先调用 lexer 模块对脚本代码的词素进行扫描和分析后,再调用parser 模块进行解析,最后调用interpreter 模块进行解释,从而实现解释器的功能。
lexer实现
lexer部分本人采用了logos进行实现,直接返回分析后的token list。详见token.rs部分
parser实现
核心数据结构便是一棵抽象语法树(Abstract Syntax Tree,AST),采用了智能指针Box<>,节点部分如下:
1 | /* |
建立AST的部分利用了lalrpop进行实现,以下面这段为例进行分析:
1 | pub Statement: Box<ast::Statement> = { |
“global” name:“identifier” “=” <init: Expression> “;” => { … }:这个分支表示一个全局变量声明语句,它以 “global” 关键字开始,后面是一个标识符 name、等号 =、以及一个表达式 init,然后以分号 ; 结束。当这种类型的语句匹配时,它会创建一个 ast::Statement::Var 节点,其中包含了 name 和 init,并将其封装在 Box 中。
“if” “(” condition:Expression “)” then:Block “;” => { … }:这个分支表示一个条件语句(if语句),它以 “if” 关键字开始,后跟括号中的条件表达式 condition、一个代码块 then,以及分号 ;。当这种类型的语句匹配时,它会创建一个 ast::Statement::Branch 节点,其中包含了 condition 和 then,并将其封装在 Box 中。
“loop” body:Block => { … }:这个分支表示一个循环语句,以 “loop” 关键字开始,后面是一个代码块 body。当这种类型的语句匹配时,它会创建一个 ast::Statement::Loop 节点,其中包含了 body,并将其封装在 Box 中。
“speak”
“input” <input:“identifier”> “;” => { … }:这个分支表示一个输入语句,以 “input” 关键字开始,后面是一个标识符 input,以及分号 ;。当这种类型的语句匹配时,它会创建一个 ast::Statement::Input 节点,其中包含了 input,并将其封装在 Box 中。
“exit” “;” => { … }:这个分支表示一个退出语句,以 “exit” 关键字开始,后面是一个分号 ;。当这种类型的语句匹配时,它会创建一个 ast::Statement::Exit 节点,不包含任何附加信息,并将其封装在 Box 中。
Block:这个分支表示一个语句块。它没有特定的开始关键字,而是由花括号 { 和 } 包围一系列语句(<stmts:Statement*>)来定义。当这种类型的语句块匹配时,它会创建一个 ast::Statement::Block 节点,其中包含了 stmts 中的多个语句,将它们封装在 Box 中。
其余部分详见grammar.lalrpop
interpreter实现
首先需要实现解释器环境管理,实现较为简单:
本解释器唯一需要注意的是variable和value之间的一一对应,因此可以环境内部便是一个map,key=variable,value=value。
环境之间管理采用stack结构,当进入一个block时可以将父环境拷贝,然后处理新增变量,执行完该block后可以直接pop掉,并对环境进行更新
1 |
|
最重要的是update_env方法,用于比较解释器环境栈中的最后两个环境,并在倒数第二个环境中更新那些在最后一个环境中有变化的键值对。这有助于确保环境栈中的环境在嵌套时能够正确地维护变量和值之间的关联关系。
1 | fn update_env(&mut self) { |
能够正确管理环境后便是递归处理AST,详见interpreter.rs
源码
详见此处