前言 当学到机器学习时发现对pandas库和numpy库一无所知,因此不得不先补习一下数据分析的部分
matplotlib 折线图绘制与保存图片 matplotlib.pyplot模块 作用于当前图形(figure)的当前坐标系
1 import matplotlib.pyplot as plt
绘制折线 1 2 3 plt.figure() plt.plot([1 ,0 ,9 ],[4 ,5 ,6 ]) plt.show()
设置画布属性与图片保存 1 2 3 4 5 plt.figure(figsize=(),dpi=) figsize:指定图的长宽 dpi:图像的清晰度 返回fig对象 plt.savefig(path)
折线图常用方法 画出一幅比较完整的折线图
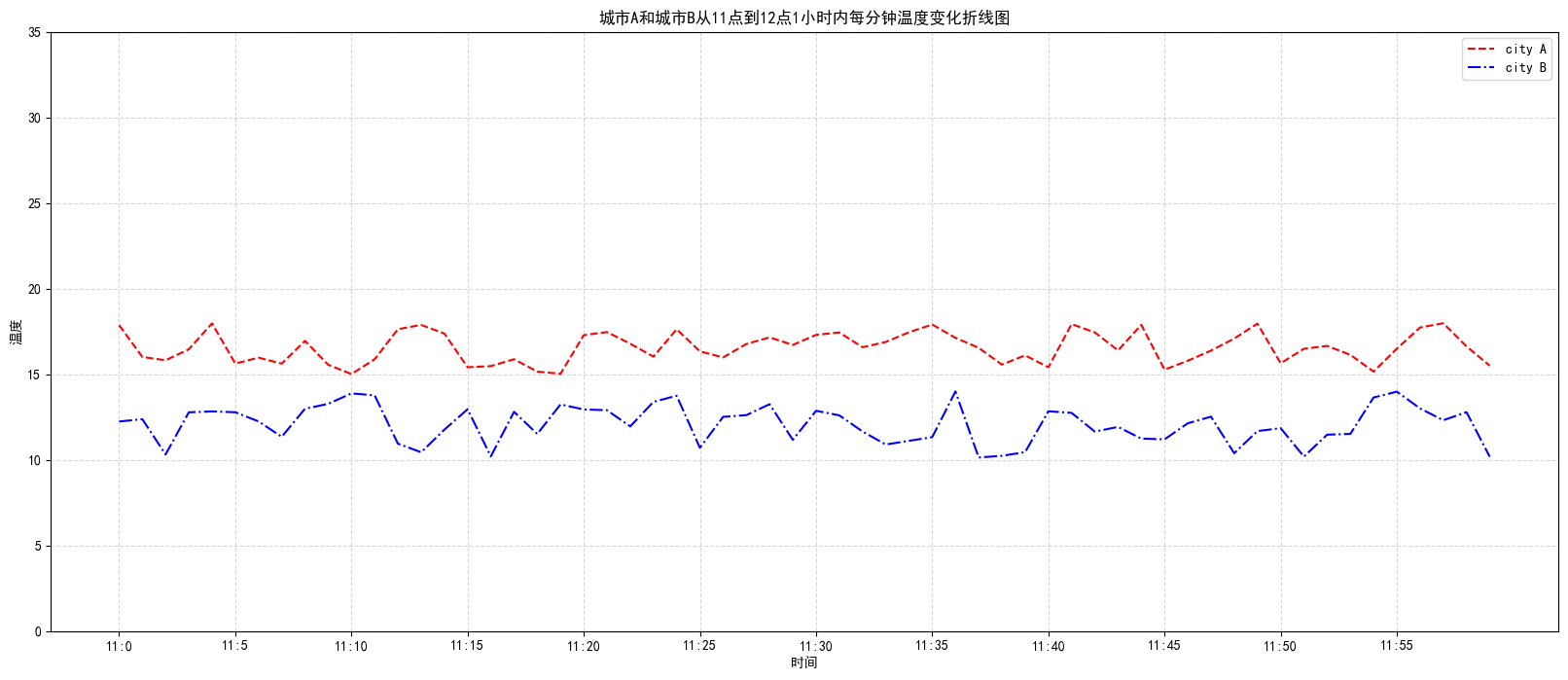
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import matplotlib.pyplot as pltimport randomplt.rcParams['font.sans-serif' ]=['SimHei' ] plt.rcParams['axes.unicode_minus' ] = False x=range (60 ) y_city1=[random.uniform(15 ,18 ) for i in x] y_city2=[random.uniform(10 ,14 ) for i in x] plt.figure(figsize=(20 ,8 ),dpi=100 ) plt.plot(x,y_city1,color="r" ,linestyle="--" ,label="city A" ) plt.plot(x,y_city2,color="b" ,linestyle="-." ,label="city B" ) x_labels=["11:{}" .format (i) for i in x] plt.xticks(x[::5 ],x_labels[::5 ]) plt.yticks(range (40 )[::5 ]) plt.grid(True ,linestyle="--" ,alpha=0.5 ) plt.xlabel(u"时间" ) plt.ylabel(u"温度" ) plt.title(u"城市A和城市B从11点到12点1小时内每分钟温度变化折线图" ) plt.legend() plt.show()
效果如下:
同一个画布,不同绘图内容
matplotlib.pyplot.subpots(nrows=1,nclos=1,**fig_kw)创建一个带有多个坐标系的图
return:figure and axes
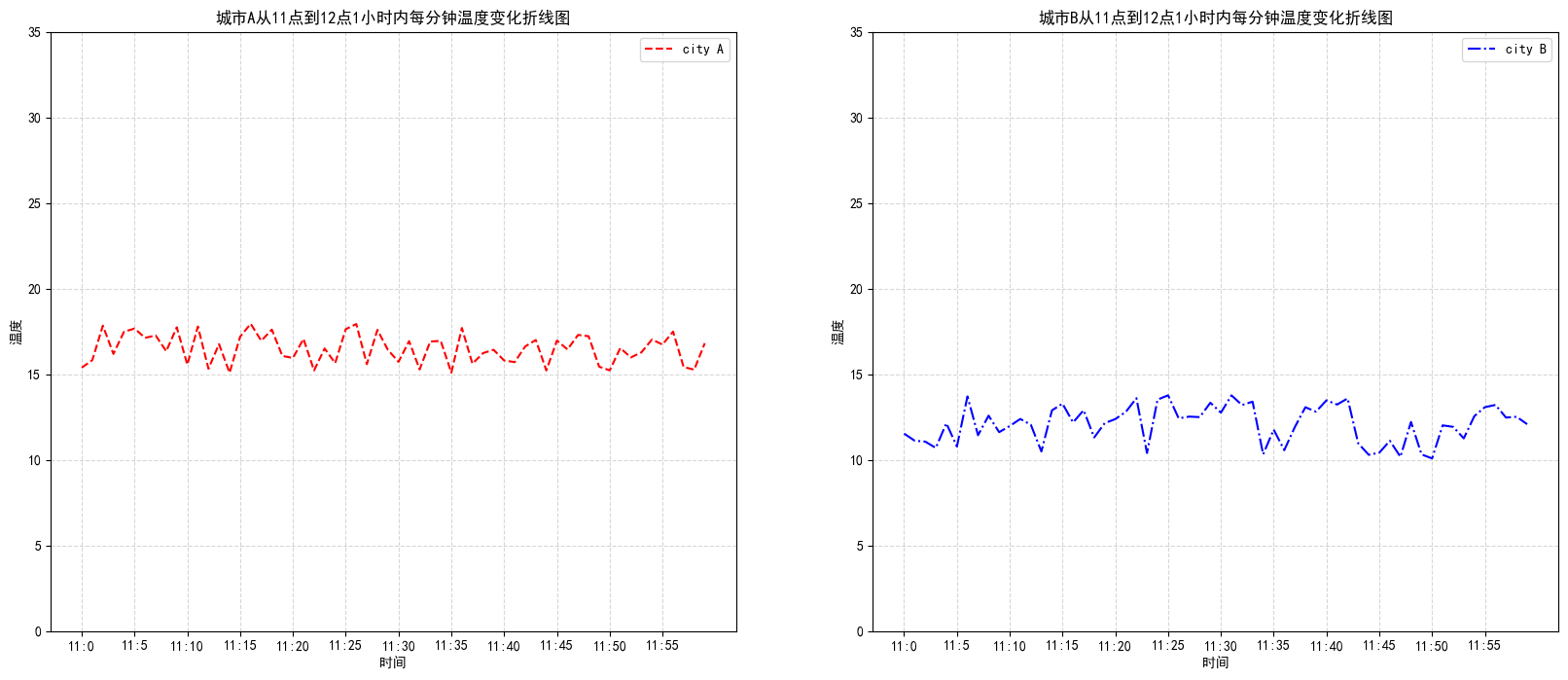
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import matplotlib.pyplot as pltimport randomplt.rcParams['font.sans-serif' ]=['SimHei' ] plt.rcParams['axes.unicode_minus' ] = False x=range (60 ) y_city1=[random.uniform(15 ,18 ) for i in x] y_city2=[random.uniform(10 ,14 ) for i in x] figure,axes=plt.subplots(nrows=1 ,ncols=2 ,figsize=(20 ,8 ),dpi=100 ) axes[0 ].plot(x,y_city1,color="r" ,linestyle="--" ,label="city A" ) axes[1 ].plot(x,y_city2,color="b" ,linestyle="-." ,label="city B" ) x_labels=["11:{}" .format (i) for i in x] axes[0 ].set_xticks(x[::5 ],x_labels[::5 ]) axes[0 ].set_yticks(range (40 )[::5 ]) axes[1 ].set_xticks(x[::5 ],x_labels[::5 ]) axes[1 ].set_yticks(range (40 )[::5 ]) axes[0 ].grid(True ,linestyle="--" ,alpha=0.5 ) axes[1 ].grid(True ,linestyle="--" ,alpha=0.5 ) axes[0 ].set_xlabel(u"时间" ) axes[0 ].set_ylabel(u"温度" ) axes[0 ].set_title(u"城市A从11点到12点1小时内每分钟温度变化折线图" ) axes[1 ].set_xlabel(u"时间" ) axes[1 ].set_ylabel(u"温度" ) axes[1 ].set_title(u"城市B从11点到12点1小时内每分钟温度变化折线图" ) axes[0 ].legend() axes[1 ].legend() plt.show()
效果如下:
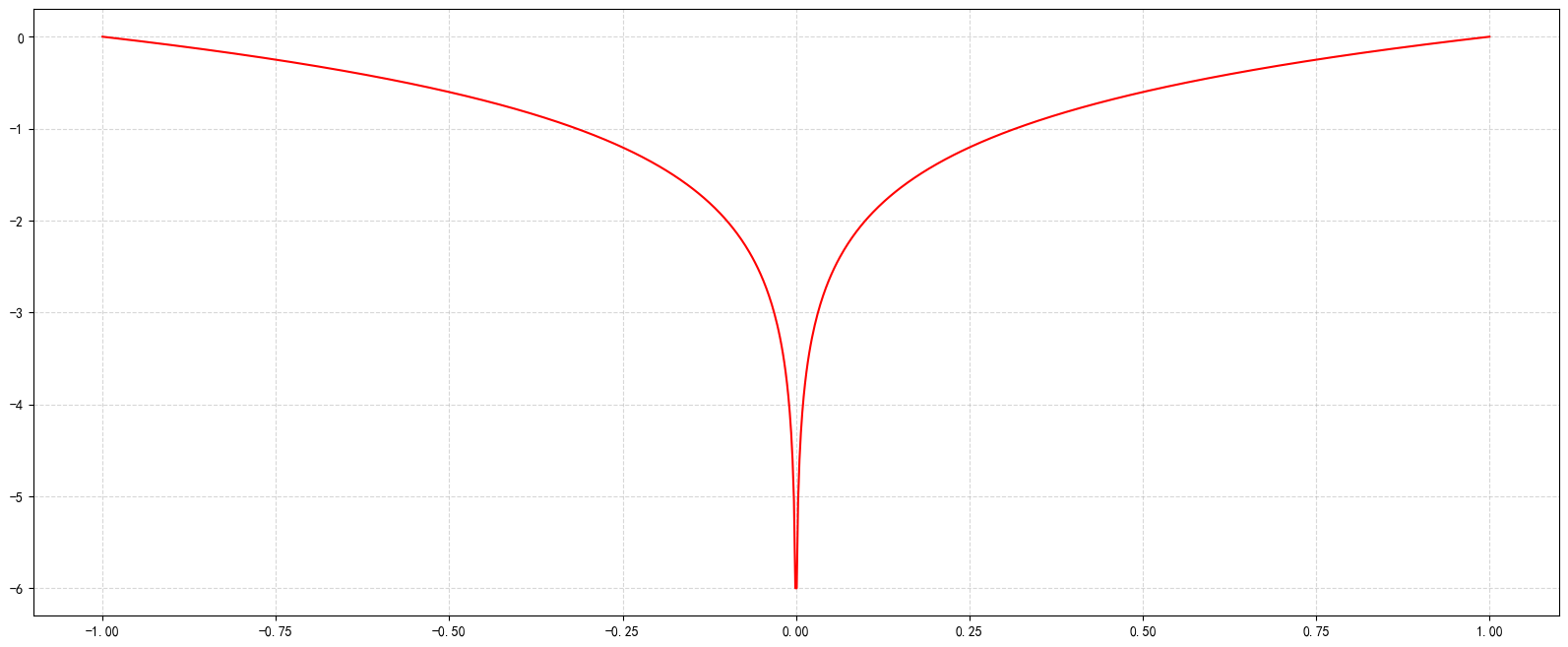
补充:如何画一个平滑的曲线(使x极其密集)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import matplotlib.pyplot as pltimport numpy as npx=np.linspace(-1 ,1 ,1000 ) y=np.log10(x*x) plt.figure(figsize=(20 ,8 ),dpi=100 ) plt.grid(linestyle="--" ,alpha=0.5 ) plt.plot(x,y,color="r" ) plt.show()
效果如下:
应用场景 某指标随时间变化
numpy 快速处理任意维度的数组
ndarray属性 shape:几行几列
ndim:维度
size:元素个数
dtype:元素类型
ndarray方法 生成数组的方法 生成0和1的方法 np.ones(shape[rows,cols]) 生成若干个1
np.zeros(shape[rows,cols]) 生成若干个0
从现有数组生成 np.array(a array) 深拷贝
np.asarray(a array) 浅拷贝
np.copy(a array) 深拷贝
生成固定范围的数据 np.linspace(start,stop,num,endpoint,retstep,dtype)
start 序列的起始值
stop 序列的终止值
num 要生成的等间隔样例数量,默认为50
endpoint 序列中是否包含stop位,默认为ture
retstep 如果为true,返回样例,以及连续数字之间的步长
dtype 输出ndarray的数据类型
生成随机数组 均匀分布:np.random.uniform(low,high,size)
正态分布:np.random.normal(loc,scale,size=None) (均值、标准差)
数组的形状、类型修改 ndarray.reshape():返回值是一个新数组代码:
1 2 3 4 5 import numpy as npdata=np.random.normal(loc=0 ,scale=1 ,size=(8 ,10 )) data data_new=data.reshape((10 ,8 )) data_new
data输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 array([[-0.28766667, -0.09677634, -1.63464481, 2.48520396, 0.52639803, 0.85846151, 0.58921122, -0.44404068, -1.39404374, 1.94189505], [ 0.06662039, -1.44664326, 0.3974641 , 0.86875591, 1.09982833, 0.381548 , -0.89180504, -1.37836702, 0.76784208, -1.95257159], [ 0.93333085, 0.16020369, -1.29682563, -0.62587936, -1.91761871, -1.13938309, 0.17948343, -0.62639323, 1.03582981, -0.6211465 ], [-1.54692473, -1.13871957, 0.42338075, -1.3883303 , -0.41907391, 1.15302419, 0.57382538, 1.80252553, 1.45490714, 0.38533545], [ 0.05260781, 0.34081529, 1.16216823, -0.72797164, -0.38720434, 0.72398337, -1.43137326, 0.460775 , 0.30293346, 1.49980074], [-0.49221772, 0.90849519, -2.71712894, 0.29107742, 0.33465442, -0.06025362, 0.25071573, -0.24853316, 0.34591986, -2.3681681 ], [ 1.29353256, -0.18892886, 1.1120222 , 0.16676639, 0.05765987, -0.1147149 , 1.18873361, 0.4555638 , -1.13531179, 0.39564516], [-0.05430111, 0.50055234, -0.26620034, 0.83248557, -0.33660892, 1.46469451, -0.37816395, 1.37236773, 1.89880811, -0.91426227]])
data_new输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 array([[-0.28766667, -0.09677634, -1.63464481, 2.48520396, 0.52639803, 0.85846151, 0.58921122, -0.44404068], [-1.39404374, 1.94189505, 0.06662039, -1.44664326, 0.3974641 , 0.86875591, 1.09982833, 0.381548 ], [-0.89180504, -1.37836702, 0.76784208, -1.95257159, 0.93333085, 0.16020369, -1.29682563, -0.62587936], [-1.91761871, -1.13938309, 0.17948343, -0.62639323, 1.03582981, -0.6211465 , -1.54692473, -1.13871957], [ 0.42338075, -1.3883303 , -0.41907391, 1.15302419, 0.57382538, 1.80252553, 1.45490714, 0.38533545], [ 0.05260781, 0.34081529, 1.16216823, -0.72797164, -0.38720434, 0.72398337, -1.43137326, 0.460775 ], [ 0.30293346, 1.49980074, -0.49221772, 0.90849519, -2.71712894, 0.29107742, 0.33465442, -0.06025362], [ 0.25071573, -0.24853316, 0.34591986, -2.3681681 , 1.29353256, -0.18892886, 1.1120222 , 0.16676639], [ 0.05765987, -0.1147149 , 1.18873361, 0.4555638 , -1.13531179, 0.39564516, -0.05430111, 0.50055234], [-0.26620034, 0.83248557, -0.33660892, 1.46469451, -0.37816395, 1.37236773, 1.89880811, -0.91426227]])
ndarray.resize():无返回值,但是对原ndarray进行修改
ndarray.T:数组转置,返回一个新数组
代码
1 2 3 4 5 import numpy as npdata=np.random.normal(loc=0 ,scale=1 ,size=(8 ,10 )) data data_new=data.T data_new
data输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 array([[ 1.12292769, 0.06189856, 1.59488317, 0.09419519, 0.61577532, -0.46587906, 0.155692 , -0.14069621, 1.43274681, -0.0971121 ], [ 0.92725129, 1.12775569, -0.90460862, -0.2160802 , -1.30754379, 0.75449727, -1.25712638, 0.61808412, -0.72735577, -0.25879189], [ 0.13580767, 0.50319859, -1.770061 , 1.03807812, 0.4309015 , 0.02787004, -0.32155091, 0.14916898, 0.12014942, 1.02765579], [-0.35585117, 0.84026015, -1.28036164, 0.49710017, 0.09688625, -0.96479185, 0.48574326, 0.58801732, 0.94178246, -0.74174535], [-0.10396494, -0.16748963, 0.5837829 , 1.85751413, 0.49852141, -1.3882722 , -1.43178106, -0.3087302 , 0.65092847, 1.04736731], [-0.98200995, 0.25860851, 0.68949501, -1.27424214, 0.61982174, -1.80155129, 0.92127167, -0.5151571 , 0.09302673, -1.9598305 ], [ 1.31156917, 2.4860945 , 0.21226952, -0.70500087, -1.95318535, 0.45431138, 0.88272884, -0.93871003, -1.62843389, 0.84345304], [ 0.82312014, -1.77914262, -0.4844116 , 0.8042173 , 0.23934763, -2.07310639, 0.3169138 , -0.04997477, 2.44392495, 0.00842191]])
data_new输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 array([[ 1.12292769, 0.92725129, 0.13580767, -0.35585117, -0.10396494, -0.98200995, 1.31156917, 0.82312014], [ 0.06189856, 1.12775569, 0.50319859, 0.84026015, -0.16748963, 0.25860851, 2.4860945 , -1.77914262], [ 1.59488317, -0.90460862, -1.770061 , -1.28036164, 0.5837829 , 0.68949501, 0.21226952, -0.4844116 ], [ 0.09419519, -0.2160802 , 1.03807812, 0.49710017, 1.85751413, -1.27424214, -0.70500087, 0.8042173 ], [ 0.61577532, -1.30754379, 0.4309015 , 0.09688625, 0.49852141, 0.61982174, -1.95318535, 0.23934763], [-0.46587906, 0.75449727, 0.02787004, -0.96479185, -1.3882722 , -1.80155129, 0.45431138, -2.07310639], [ 0.155692 , -1.25712638, -0.32155091, 0.48574326, -1.43178106, 0.92127167, 0.88272884, 0.3169138 ], [-0.14069621, 0.61808412, 0.14916898, 0.58801732, -0.3087302 , -0.5151571 , -0.93871003, -0.04997477], [ 1.43274681, -0.72735577, 0.12014942, 0.94178246, 0.65092847, 0.09302673, -1.62843389, 2.44392495], [-0.0971121 , -0.25879189, 1.02765579, -0.74174535, 1.04736731, -1.9598305 , 0.84345304, 0.00842191]])
数组的去重 ndarray.unique(ndarray):会降至一维
ndarray逻辑运算 1 2 3 4 5 6 import numpy as npdata=np.random.normal(loc=0 ,scale=1 ,size=(8 ,10 )) data>0.5 data[data>0.5 ]=1.1
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 array([[-0.44407531, 1.1 , -0.84645156, -0.01855358, 1.1 , -0.2451455 , -0.23534646, 1.1 , 1.1 , 0.15378838], [ 0.06871003, 1.1 , -0.16959721, -1.22897705, 1.1 , 1.1 , -0.47367264, 0.12408716, -0.44255715, 1.1 ], [-1.28955728, -0.93029653, 0.41018535, -1.04399455, -0.97376158, -0.21693159, -2.08449161, 0.4946256 , 1.1 , -0.047539 ], [ 0.03313902, 1.1 , 1.1 , 0.05738063, -1.08294878, 1.1 , 1.1 , 1.1 , 0.2188831 , -0.00811251], [ 1.1 , -1.17501414, 1.1 , -0.12566327, 1.1 , 0.3834531 , 1.1 , 1.1 , 1.1 , 1.1 ], [ 0.48011899, 0.17309247, 0.32507344, 1.1 , 1.1 , -1.82158113, 0.15579367, 0.38989207, -0.32709191, 1.1 ], [-1.14911619, 0.27446299, 1.1 , 0.46487617, 1.1 , -1.07065446, -1.45992222, -0.14370483, -0.71917344, 0.17831895], [-0.96808292, 1.1 , -0.60129197, 0.14332592, -1.11110068, 0.29691849, -0.43130773, -0.8395376 , -1.71889086, -0.55248602]])
ndarray通用判断函数 np.all():传入一组布尔值,全部都是True才会返回True
np.any():传入一组布尔值,全部都是False才会返回False
ndarray三元运算符 np.where(一组布尔值,True位置的值,False位置的值)
复合逻辑需要结合np_logical_or()和np_logical_and()
1 2 3 4 import numpy as npdata=np.random.normal(loc=0 ,scale=1 ,size=(8 ,10 )) print (data)np.where(data>0 ,1 ,-1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [[ 0.53417648 -1.53770341 -1.1794381 3.33181925 0.09646391 -1.09357423 0.22700084 -0.15417727 -0.47342351 -0.34804038] [ 0.86455628 -0.32328798 -0.31060284 -1.33676651 0.37823584 1.47709378 0.25716079 1.83478704 -0.74654684 -0.20445119] [ 1.98614157 -0.52191484 -0.49158282 -0.69238352 2.15836548 -0.70470615 0.25653631 1.27603046 -2.26895973 0.36308765] [-1.68540682 1.50926967 0.19324415 0.00632465 0.21712198 -0.90152505 1.40412996 -1.90441428 -1.99958765 0.31012906] [-0.86909586 0.310891 0.22178655 3.01480159 0.33511726 0.83585426 -2.44763916 2.15409659 -1.77047869 1.08092591] [-0.77654287 1.05527413 -0.27634714 1.68719826 -0.7590273 0.37367929 0.92548002 1.36187239 1.67589982 -0.76392006] [ 0.12200505 -1.37078607 -1.03024655 -0.85297479 -1.01158078 0.50459932 0.02541402 1.7660727 -0.39369918 0.64408087] [ 0.47485326 -0.62424081 1.83628553 0.33466764 -1.09334708 1.0899985 -0.68714199 -1.14327089 -0.03528435 -0.78234659]] array([[ 1, -1, -1, 1, 1, -1, 1, -1, -1, -1], [ 1, -1, -1, -1, 1, 1, 1, 1, -1, -1], [ 1, -1, -1, -1, 1, -1, 1, 1, -1, 1], [-1, 1, 1, 1, 1, -1, 1, -1, -1, 1], [-1, 1, 1, 1, 1, 1, -1, 1, -1, 1], [-1, 1, -1, 1, -1, 1, 1, 1, 1, -1], [ 1, -1, -1, -1, -1, 1, 1, 1, -1, 1], [ 1, -1, 1, 1, -1, 1, -1, -1, -1, -1]])
统计指标的方法 np.min(ndarray,axis(行标)):最小值
np.max(ndarray,axis(行标)):最大值
np.argmin(ndarray,axis(行标)):最小值索引
np.argmax(ndarray,axis(行标)):最大值索引
np.median(ndarray,axis(行标)):中位数
np.mean(ndarray,axis(行标)):平均值
np.std(ndarray,axis(行标)):标准差
np.var(ndarray,axis(行标)):方差
数组与数组的运算 满足广播机制:两个数组满足维度相等, shape(相对应位置为1)
矩阵运算 np.mat():将数组转换为矩阵类型
np.matmul(mat1,mat2):矩阵叉乘
np.dot(mat1,mat2):矩阵点乘
合并两个数组,分割一个数组 numpy.hstack(ndarray1,ndarray2):按行进行拼接
numpy.vhtack(ndarray1,ndarray2)):按列进行拼接
numpy.split(nadrray,…):第一个参数是数组,后面的参数是按照索引分割
pandas DataFrame 既有行索引,又有列索引的二位数组,而且显示数据更为友好
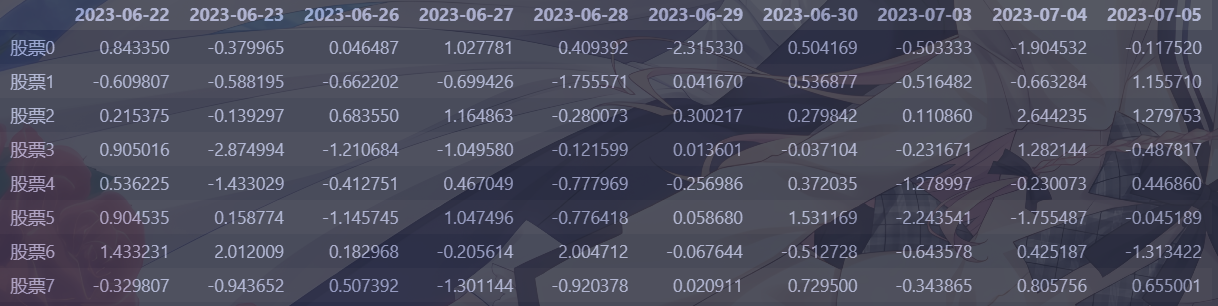
1 2 3 4 5 6 7 8 import numpy as npimport pandas as pd data=np.random.normal(loc=0 ,scale=1 ,size=(8 ,10 )) rowname=["股票{}" .format (i) for i in range (8 )] colname=pd.date_range(start="20230622" ,periods=10 ,freq="B" ) pd.DataFrame(data,index=rowname,columns=colname)
输出:
属性:shape,index,columns,values,T
方法:head(num),tail(num) 返回前/后num行
索引的修改必须全部修改
设置新索引:set_index(keys,drop=True)
keys:列索引名或者列索引名称的列表 drop:删除原先的列
Series 带索引的一维数组,index获取索引,values获取值
基本数据操作 直接索引(data[][])(先列后行)、按名字索引(data.log[][])、按数字索引(data.iloc[][])
排序:df.sort_values(key=[],ascending=)对内容进行排序,默认升序
df.sort_index() 对索引进行排序,默认升序
基本运算操作 describe完成综合统计
max完成最大值计算
min完成最小值计算
mean完成平均值计算
std完成标准差计算
idxmin、idxmax完成最大值最小值的索引使用cumsum等实现累计分析
逻辑运算符号实现数据的逻辑筛选(多个筛选条件需要加括号定义优先级)
isin(values)怕那段值是否为values
query(condition_expr)查询字符串
add等实现数据间的加法运算
apply(func,axis=0)函数实现数据的自定义处理 (axis=0为列运算,axis=1为行运算)
cumadd(n)/cummax(n)/cummin(n)/cumprod(n):计算前n个数的和/最大值/最小值/积
pandas画图 DataFrame.plot (x=None, y=None, kind=“line”)
x : label or position, default None
y : label, position or list of label, positions, default None
Allows plotting of one column versus another
kind : str
“line” : line plot (default)
“bar” : vertical bar plot
“barh” : horizontal bar plot
“hist” : histogram
“pie” : pie plot
“scatter” : scatter plot
文件读取 pd.read_csv(filename,usecol=[])
缺省值为null的处理 读取样本数据,发现存在缺失值 点此下载样本数据
1 2 3 4 5 6 7 import pandas as pdimport numpy as npmovie=pd.read_csv("IMDB-Movie-Data.csv" ) pd.isnull(movie).any ()
输出
1 2 3 4 5 6 7 8 9 10 11 12 13 Rank False Title False Genre False Description False Director False Actors False Year False Runtime (Minutes) False Rating False Votes False Revenue (Millions) True Metascore True dtype: bool
删除含有缺失值的样本 判断数据里是否存在NaN: pd.isnull(df):是缺失值标记为True
pd.notnull(df):不是缺失值标记为True
删除含有缺失值的样本 df.dropna(inplace=False):返回一个不含有缺失值样本的数据
1 movie_del=movie.dropna()
替换/插补 如何处理NaN?
判断数据里是否存在NaN: pd.isnull(df):是缺失值标记为True
pd.notnull(df):不是缺失值标记为True
填补缺失值 df.fillna(value,inplace=False)
1 2 movie_add=movie.fillna(movie["Revenue (Millions)" ].mean()) movie_add=movie.fillna(movie["Metascore" ].mean())
缺省值为其他符号的处理 1 2 3 4 5 6 7 8 9 import pandas as pdimport numpy as nppath="https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data" name = ["Sample code number" , "Clump Thickness" , "Uniformity of Cell Size" , "Uniformity of Cell Shape" , "Marginal Adhesion" , "Single Epithelial Cell Size" , "Bare Nuclei" , "Bland Chromatin" , "Normal Nucleoli" , "Mitoses" , "Class" ] data=pd.read_csv(path,names=name) data_new=data.replace(to_replace="?" ,value=np.nan) data_new.isnull().any ()
输出
1 2 3 4 5 6 7 8 9 10 11 12 Sample code number False Clump Thickness False Uniformity of Cell Size False Uniformity of Cell Shape False Marginal Adhesion False Single Epithelial Cell Size False Bare Nuclei True Bland Chromatin False Normal Nucleoli False Mitoses False Class False dtype: bool
其余操作相同
1 2 3 4 data_new.dropna(inplace=True ) data_new=data_new.fillna(data_new["Bare Nuclei" ].mean())
数据离散化 one-hot编码 1)分组
自动分组pd.qcut(data,bins)
自定义分组pd.cut(data,[])
返回分好组后的series
2)将转换后的结果转换成one-hot编码
pd.get_dummies(sr,prefixm)
代码(非自定义分组)
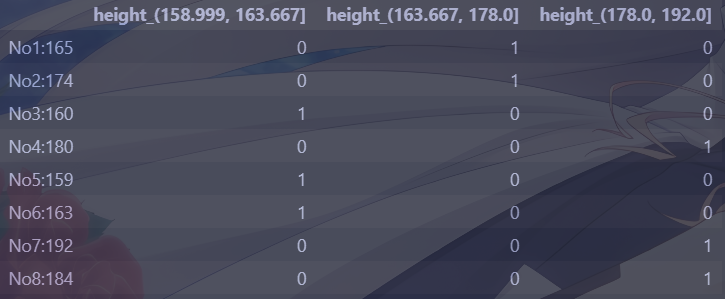
1 2 3 4 5 6 7 import pandas as pddata = pd.Series([165 ,174 ,160 ,180 ,159 ,163 ,192 ,184 ], index=['No1:165' , 'No2:174' ,'No3:160' , 'No4:180' , 'No5:159' , 'No6:163' , 'No7:192' , 'No8:184' ]) sr = pd.qcut(data, 3 ) pd.get_dummies(sr, prefix="height" )
输出
代码(自定义分组)
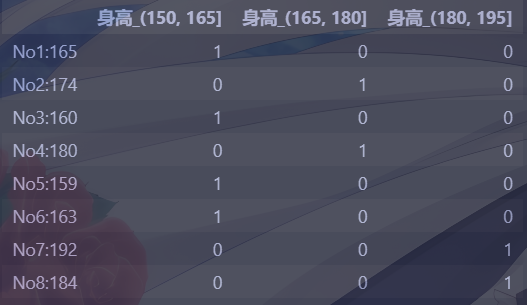
1 2 3 4 5 import pandas as pddata = pd.Series([165 ,174 ,160 ,180 ,159 ,163 ,192 ,184 ], index=['No1:165' , 'No2:174' ,'No3:160' , 'No4:180' , 'No5:159' , 'No6:163' , 'No7:192' , 'No8:184' ]) bins = [150 , 165 , 180 , 195 ] sr = pd.cut(data, bins) pd.get_dummies(sr, prefix="身高" )
输出
数据合并 pd.concat([data1, data2], axis=1) 按照行或列进行合并,axis=0为列索引,axis=1为行索引
pd.merge(left, right, how=‘inner’, on=[], left_on=None,right_on=None,left_index=False, right_index=False, sort=True,suffixes=(‘_x,’_y’).copy=True,indicator=False,validate=None)
可以指定按照两组数据的共同键值对合并或者左右各自
left : A DataFrame object
right :Another DataFrame object
on : Columns (names) to join on. Must be found in both the left and right DataFrame objects.
left_on=None,right_on=None:指定左右键
连接方式:
Merge method SQL Join Name Description left LEFT OUTER JOIN Use keys from left frame only right RIGHT OUTER JOIN Use keys from right frame only outer FULL OUTER JOIN Use union of keys from both frames inner INNER JOIN Use intersection of keys from both frames
交叉表与透视表 pd.crosstab(value1,value2)
pd.pivot_table([],index=[])
分组与聚合 df.groupby(by=[],as_index=False)
代码 点此下载样本数据
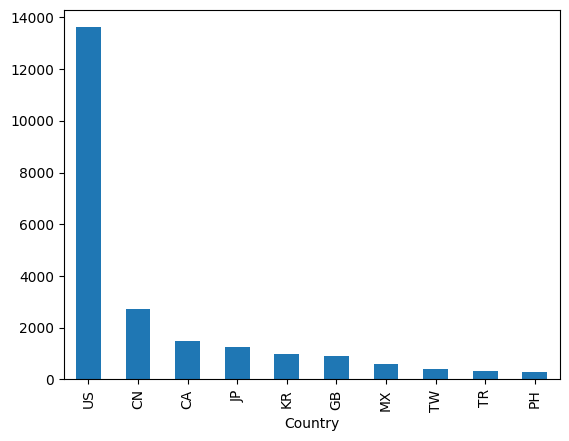
1 2 3 4 5 6 7 import pandas as pdimport numpy as npdata=pd.read_csv("directory.csv" ) data_new=data.groupby(by="Country" ) data_new["Store Number" ].count().sort_values(ascending=False )[:10 ].plot(kind="bar" )
输出
综合案例 点此下载样本数据
问题1:获取这些电影数据中评分的平均分,导演的人数等信息
1 2 3 4 print ("The average rate of movies is {}" .format (round (movie["Rating" ].mean(),2 )))print ("The number of movies' director is {}" .format (movie["Director" ].unique().size))
输出:
1 2 The average rate of movies is 6.72 The number of movies' director is 644
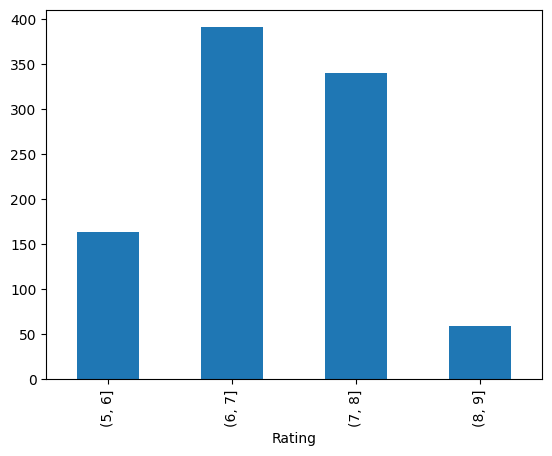
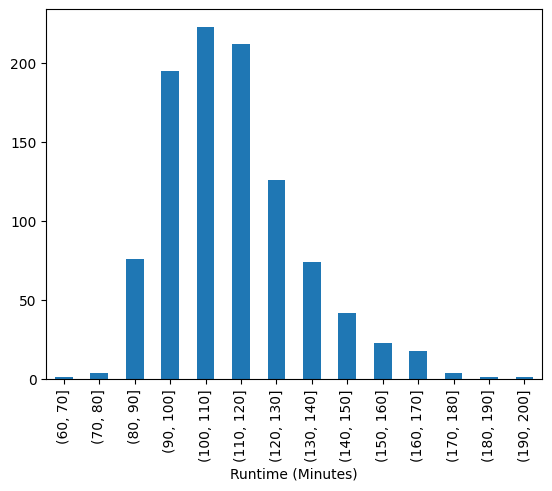
问题2:对于这一组电影数据,获取rating,runtime的分布情况
1 2 3 4 5 6 7 8 bins=[5 ,6 ,7 ,8 ,9 ] rating = pd.cut(movie["Rating" ], bins) rating.value_counts().sort_index().plot(kind="bar" ) bins=[60 ,70 ,80 ,90 ,100 ,110 ,120 ,130 ,140 ,150 ,160 ,170 ,180 ,190 ,200 ] runtime = pd.cut(movie["Runtime (Minutes)" ], bins) runtime.value_counts().sort_index().plot(kind="bar" )
输出:
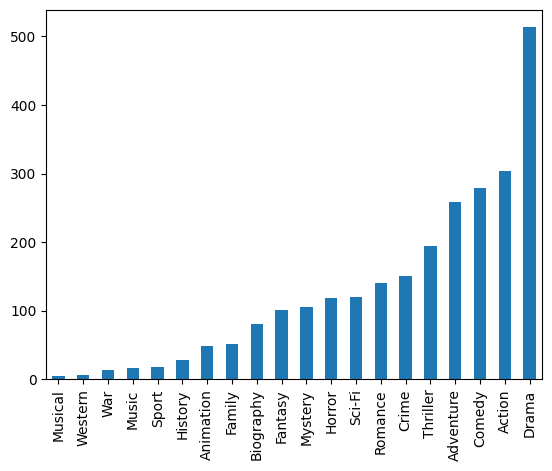
问题3:对于这一组电影数据,统计电影分类(genre)的情况
1 2 3 4 5 6 7 8 9 10 11 flatten_list = [j for i in [i.split("," ) for i in movie["Genre" ]] for j in i] kinds = list (set (flatten_list)) genre = pd.Series(np.zeros([1 ,len (kinds)])[0 ], index=kinds).astype("int32" ) for i in flatten_list : genre[i]=genre[i]+1 genre.sort_values().plot(kind="bar" )
输出:
点此查看源码