题目背景与目标
题目背景:
GAMMA银行是一家私人银行,经营各种银行产品,如储蓄账户、活期账户、投资产品、信贷产品等。该行还向现有客户交叉销售产品,为此,客户使用不同的通信方式,如电视广播、电子邮件、网上银行推荐、手机银行等。在这种情况下,GAMMA客户银行希望将其信用卡交叉销售给现有客户。银行已经确定了一组有资格使用这些信用卡的客户。现在,银行正在寻求您的帮助,以确定可能对推荐的信用卡表现出更高意向的客户。
分析目标:
通过银行收集到的客户属性数据,预测客户是否对当前推出的信用卡感兴趣
资料获取
训练集
测试集
题目描述
分析与实现
特征工程
存在字段ID ,Age ,Region_Code ,Occupation ,Channel_Code ,Vintage ,Credit_Product ,AvgAccountBalance ,Is_Active ,Is_Lead(Target)
很明显,ID字段不可能和目标有任何关系,于是乎直接移除。而地区字段仅仅是RG+数字,于是把RG去除就是Region_Code的数字特征
1
2
| train=train.drop(["ID"],axis=1)
train['Region_Code']=train['Region_Code'].apply(lambda x:x[2:]).astype('int64')
|
而后,将可能有关系的字段先可视化一下
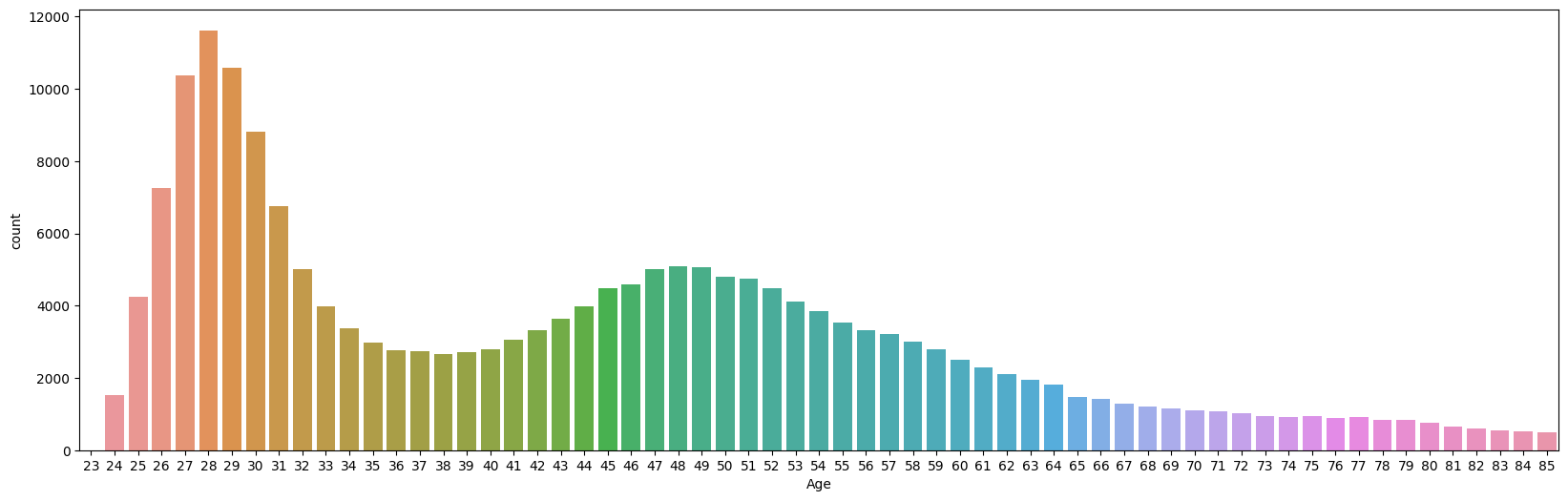
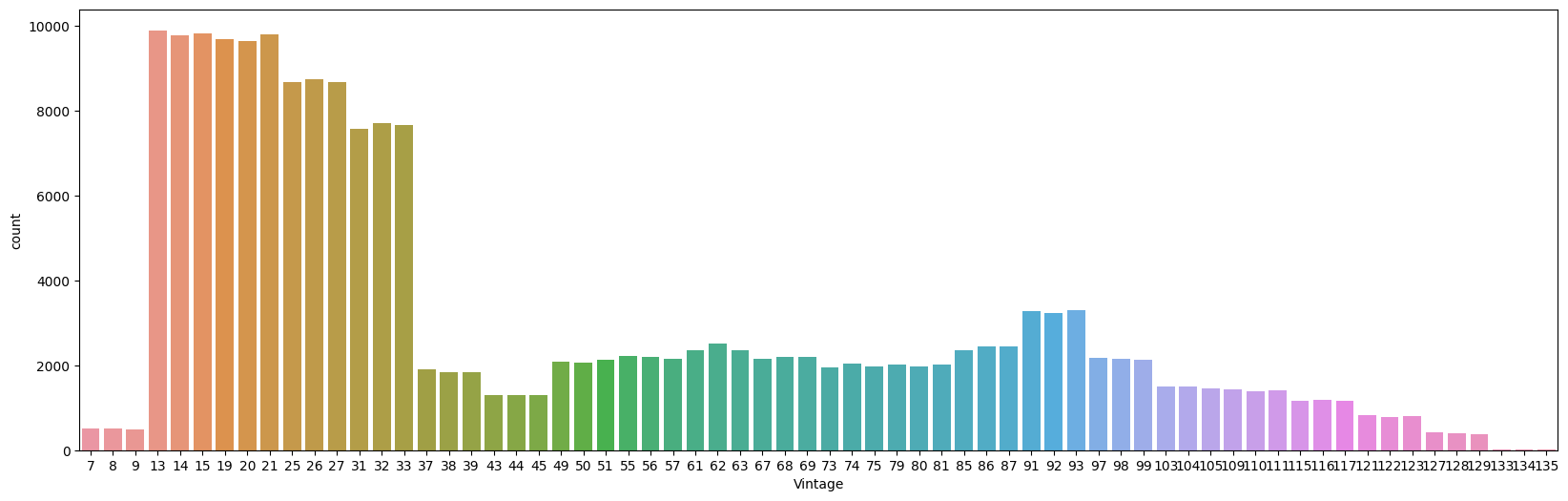
这两个字段应该也有办法处理一下,但是我不会(´;ω;)
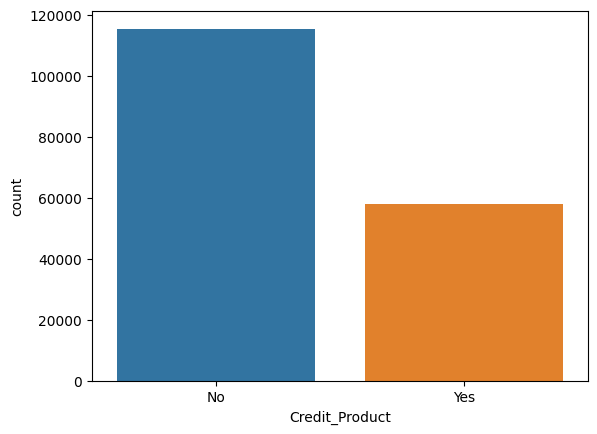
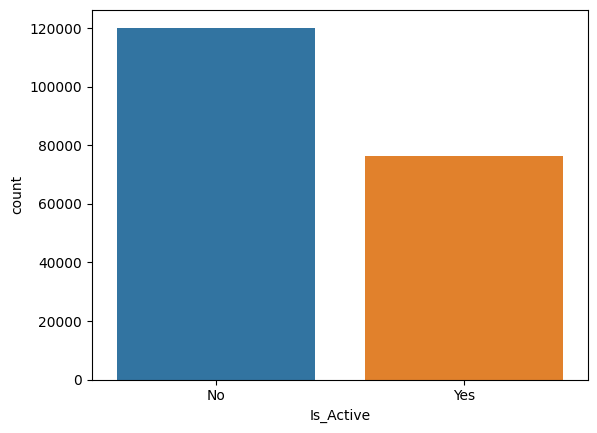
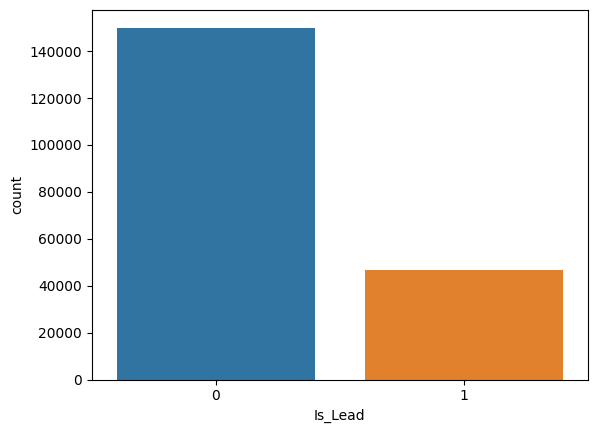
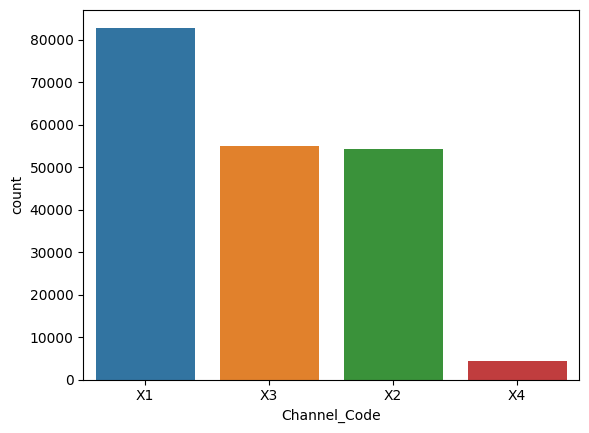
根据图片,需要处理Is_Lead,因为Is_Lead=1的样本量太少了,需要欠采样多数类
1
2
3
4
5
6
7
8
| # 欠采样多数类
df_majority = train[train['Is_Lead']==0]
df_minority = train[train['Is_Lead']==1]
df_majority_undersampled = resample(df_majority,replace=True,n_samples=len(df_minority),random_state=0)
# 结合少数类和过采样的多数类
df_undersampled = pd.concat([df_minority, df_majority_undersampled])
df_undersampled['Is_Lead'].value_counts()
train=df_undersampled
|
首先对字段下为String的部分转换为数字特征
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
train["Gender"] = train["Gender"].replace({"Male": 1, "Female": 0}).astype("int32")
train["Is_Active"] = train["Is_Active"].replace({"Yes": 1, "No": 0}).astype("int32")
train["Credit_Product"] = train["Credit_Product"].replace({"Yes": 1, "No": 0})
encoded_data = pd.get_dummies(train["Occupation"], prefix="Occupation").replace({True: 1, False: 0})
train = pd.concat([train.iloc[:, :-1], encoded_data, train.iloc[:, -1]], axis=1)
train=train.drop(["Occupation"],axis=1)
train = pd.get_dummies(train, columns=['Channel_Code'], prefix=['X']).replace({True: 1, False: 0})
column_to_move = train.columns[-5]
column_data = train[column_to_move]
train = train.drop(column_to_move, axis=1)
train[column_to_move] = column_datav
|
之后打算查看各特征值与是否可能成为信用卡客户的相关性
1
2
| df_corr_lead=train.corr()[u'Is_Lead'].sort_values(ascending=False)
df_corr_lead=df_corr_lead.drop(['Is_Lead'],axis=0)
|
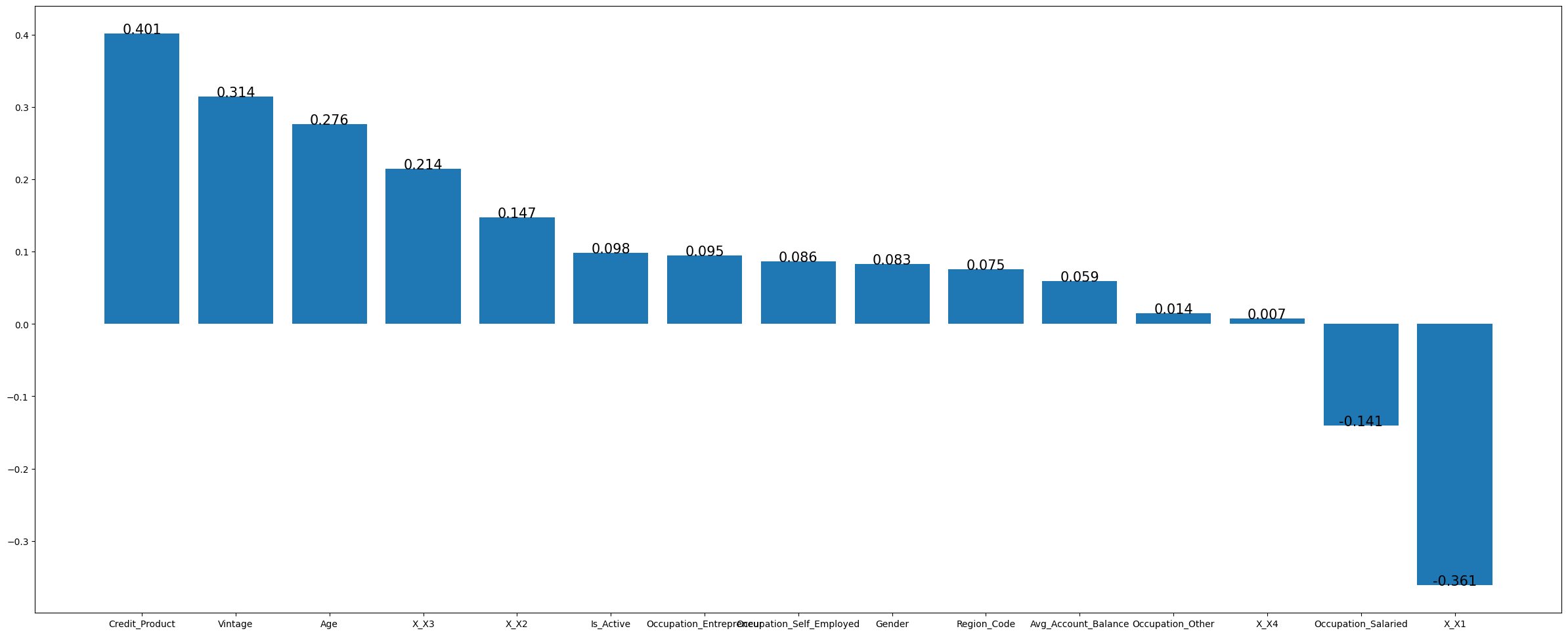
发现Channel_Code ,Vintage ,Credit_Product这三个与Is_Lead关系很密切
那么检查一下是否有缺失吧
1
2
| # 判断是否存在缺失值
pd.isnull(train).any()
|
结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| Gender False
Age False
Region_Code False
Vintage False
Credit_Product True
Avg_Account_Balance False
Is_Active False
Occupation_Entrepreneur False
Occupation_Other False
Occupation_Salaried False
Occupation_Self_Employed False
X_X1 False
X_X2 False
X_X3 False
X_X4 False
Is_Lead False
dtype: bool
|
oops,Credit_Product居然有缺失,它又是和Is_Lead紧密相关,肯定要预测一下
Credit_Product的处理
首先分出Credit_Product的测试集和训练集
1
2
3
4
|
missing_credit_product = train[train["Credit_Product"].isnull()]
non_missing_credit_product = train[train["Credit_Product"].notnull()]
|
然后查看各特征值与是否可能成为信用卡客户的相关性
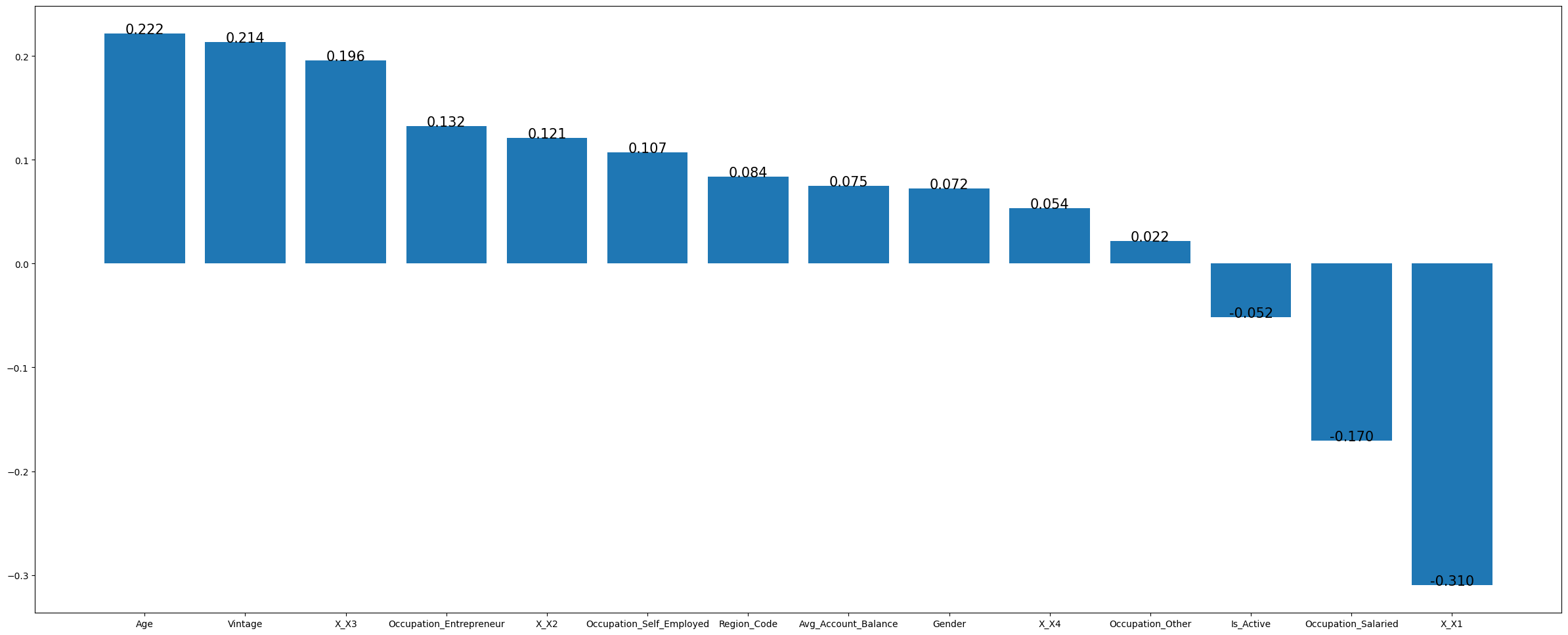
感觉并没有特别突出的,那就全部训练吧
PS:我尝试对Credit_Product字段也进行欠采样多数类,但是AUC反而变低了,应该是欠采样多数类后样本较少的缘故
1
2
3
4
5
6
7
8
9
|
from sklearn.model_selection import train_test_split
data=non_missing_credit_product.drop(["Is_Lead", "Credit_Product"], axis=1)
x_train,x_test,y_train,y_test=train_test_split(data,non_missing_credit_product["Credit_Product"],test_size=0.2,random_state=22)
from sklearn.preprocessing import StandardScaler
transfer=StandardScaler()
x_train_new=transfer.fit_transform(x_train)
x_test_new=transfer.transform(x_test)
|
模型测试了KNN,逻辑回归、随机森林和lightgbm,lightgbm效果最好
1
2
3
4
5
6
7
8
9
10
11
| import lightgbm as lgb
from sklearn.metrics import roc_auc_score
lgb_classifier = lgb.LGBMClassifier(n_estimators=80, random_state=40)
lgb_classifier.fit(x_train_new, y_train)
y_pred_prob = lgb_classifier.predict_proba(x_test_new)[:, 1]
auc_score = roc_auc_score(y_test, y_pred_prob)
print("AUC Score:", auc_score)
|
AUC Score: 0.7671483718923551
填充好missing_credit_product的值后就开始预测Is_Lead
预测Is_Lead
1
2
3
4
5
6
7
|
data=train.drop(["Is_Lead"], axis=1)
x_train,x_test,y_train,y_test=train_test_split(data,train["Is_Lead"],test_size=0.25,random_state=42)
transfer=StandardScaler()
x_train_new=transfer.fit_transform(x_train)
x_test_new=transfer.transform(x_test)
|
模型依旧选择了lightgbm,但是采用了贝叶斯优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| from bayes_opt import BayesianOptimization
def lgb_cv(n_estimators, learning_rate, max_depth, num_leaves, min_child_samples, subsample, colsample_bytree):
n_estimators = int(n_estimators)
max_depth = int(max_depth)
num_leaves = int(num_leaves)
min_child_samples = int(min_child_samples)
lgb_classifier = lgb.LGBMClassifier(
n_estimators=n_estimators,
learning_rate=learning_rate,
max_depth=max_depth,
num_leaves=num_leaves,
min_child_samples=min_child_samples,
subsample=subsample,
colsample_bytree=colsample_bytree,
random_state=40
)
lgb_classifier.fit(x_train_new, y_train)
y_pred_prob = lgb_classifier.predict_proba(x_test_new)[:, 1]
auc_score = roc_auc_score(y_test, y_pred_prob)
return auc_score
pbounds = {
'n_estimators': (150, 220),
'learning_rate': (0.02, 0.09),
'max_depth': (10, 15),
'num_leaves': (20, 100),
'min_child_samples': (5, 50),
'subsample': (0.5, 0.7),
'colsample_bytree': (0.6, 1.0)
}
optimizer = BayesianOptimization(
f=lgb_cv,
pbounds=pbounds,
random_state=42
)
optimizer.maximize(init_points=10, n_iter=100)
best_params = optimizer.max['params']
best_auc = optimizer.max['target']
print("Optimal Hyperparameters:")
print(best_params)
print("Best AUC Score:", best_auc)
|
超参数:
‘colsample_bytree’: 0.610865775300284
‘learning_rate’: 0.0805284415086373
‘max_depth’: 13.707039129713081
‘min_child_samples’: 7.262616569392997
‘n_estimators’: 215.9489533887009
‘num_leaves’: 87.00033587605007
‘subsample’: 0.620344288616325
Best AUC Score: 0.8755665739616039
后记
这个题给我的感觉是特征工程比较重要,最开始选择把Credit_Product填为平均值0.333333,没有进行任何其他操作,效果很差劲,进行预测之后,虽然AUC仅仅0.76,但是对于最终AUC提升还是比较明显的
源码