Operating System
Introduction
What is an Operating System?
Referee
Manage sharing of resources, Protection,Isolation
- Resource allocation, isolation, communication
Illusionist
Provide clean, easy to use abstractions of physical resources
Infinite memory, dedicated machine
Higher level objects:files, users, messages
Masking limitations, virtualization
Glue
Common services
Storage, Window system, Networking
Sharing, Authorization
Look and feel
Fundamental OS Concepts
OS Abstracts underlying hardware
1 | Application |
OS Goals
Remove software/hardware quirks (fight complexity)
Optimize for convenience, utilization, reliability,…(help the programmer)
Protecting Processes & The Kernel
- Run multiple applications and:
- Keep them from interfering with or crashing the operating system- Keep them from interfering with or crashing each other
- Run multiple applications and:
Virtual Machines
Virtualize every detail of a hardware configuration soperfectly that you can run an operating system (and manyapplications)on top of it.
Provides isolation
Complete insulation from change
The norm in the Cloud (server consolidation)
System Virtual Machines: Layers of OSs
Useful for OS development
When OS crashes, restricted to one VM
Can aid testing/running programs on other OssUse for deployment
Running different OSes at the same time
Run Programs
Load instruction and data segments of executable file into memory
Create stack and heap
“Transfer control to program”
Provide services to program
Thread of Control
Thread: Single unique execution context
A thread is executing on a processor (core) when it is resident in the processor
registers
Threads are a mechanism for concurrency (overlapping execution). However, they can also run in paralle (simultaneous execution)
Resident means: Registers hold the root state (context) of the thread:
Including program counter (PC) register & currently executing instruction
Including intermediate values for ongoing computations
Stack pointer holds the address of the top of stack (which is in memory)
The rest is “in memory"
A thread is suspended (not executing) when its state is not loaded (resident)
into the processor
State shared by all threads in process/address space
Content of memory (global variables, heap)
l/O state (file descriptors, network connections, etc)
State “private" to each thread
Kept in TCB in memory = Thread Control Block
CPU registers (including, program counter)
Execution stack
Parameters, temporary variables
Return PCs are kept while called procedures are executing
Motivation for Threads
Operating systems must handle multiple things at once.
Threads are a unit of concurrency provided by the OS
Each thread can represent one thing or one task
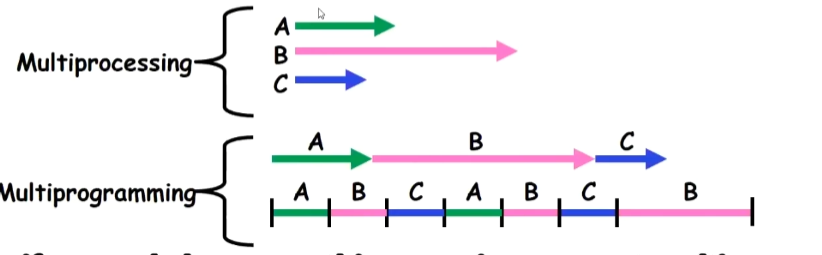
Multiprocessing vs.Multiprogramming
Some Definitions:
Multiprocessing:Multiple CPUs(cores)
Multiprogramming: Multiple jobs/processes
Multithreading: Multiple threads/processes
Concurrency is about handling multiple things at once.
Parallelism is about doing multiple things simultaneously
What does it mean to run two threads concurrently?
Scheduler is free to run threads in any order and interleaving
Thread may run to completion or time-slice in big chunks or small chunks
Correctness with Concurrent Threads
Non-determinism:
Scheduler can run threads in any order
Scheduler can switch threads at any time
This can make testing very difficult
Threads Mask l/O Latency
A thread is in one of the following three states:
RUNNING: running
READY: eligible to run, but not currently running
BLOCKED: ineligible to run
If a thread is waiting for an I/O to finish, the OS marks it as BLOCKED.Once the I/O finally finishes, the OS marks it as READY
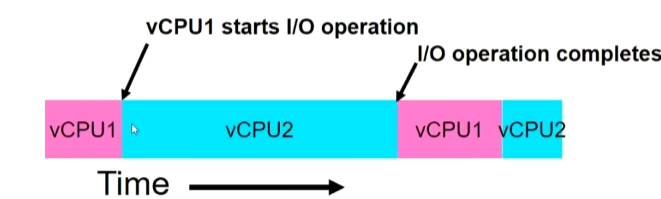
vCPU1 is running, and vCPU2 is in the ready queue. Once vCPU1 receives an I/O operation, it will enter the blocked, and vCPU2 will start running. When vCPU1 completes the I/O operation, it will resume execution.
Illusion of Multiple Processors
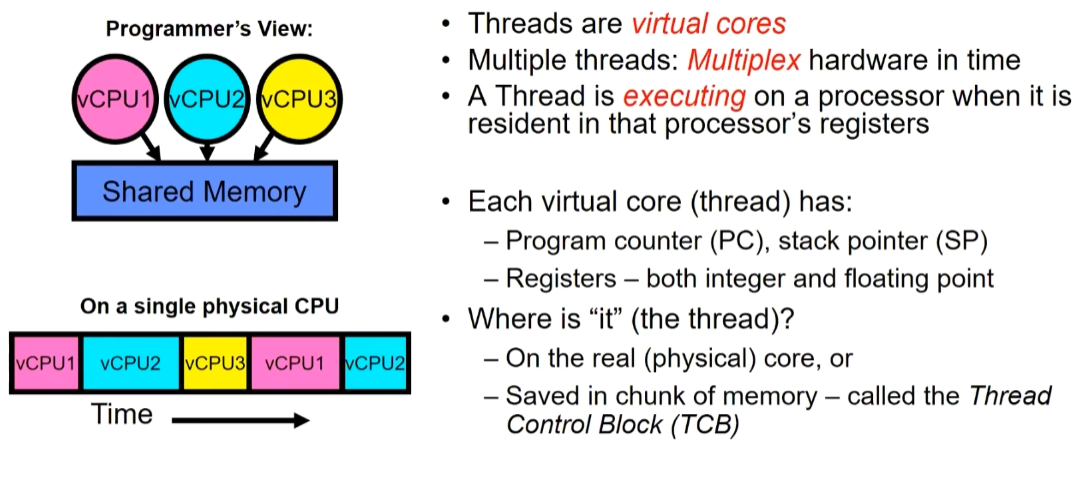
Let’s assume there’s only one physical processor with a single core, allowing only one execution thread on the hardware at any given time. But now, what we desire is to have multiple CPUs, or the illusion of multiple CPUs running simultaneously, so that we can have multiple threads executing concurrently. From a programmer’s perspective, it appears that I have a bunch of things all running, and they all share memory.
At T1:VCPU1 on real core, VCPU2 in memory
Saved PC,SP…in VCPU1’s thread control block (memory)
Loaded PC,SP,…from VCPU2’s TCB,jumped to PC
At T2: VCPU2 on real core,VCPU1 in memory
Protection
Operating System must protect itself from user programs
Reliability: compromising the operating system generally causesit to crash
Security: limit the scope of what threads can do
Privacy: limit each thread to the data it is permitted to access
Fairness: each thread should be limited to its appropriate share of system resources (CPU time, memory, I/O,etc)
OS must protect User programs from one another
Prevent threads owned by one user from impacting threads owned by another user
Example: prevent one user from stealing secret information from another user
Simple Protection:Base and Bound
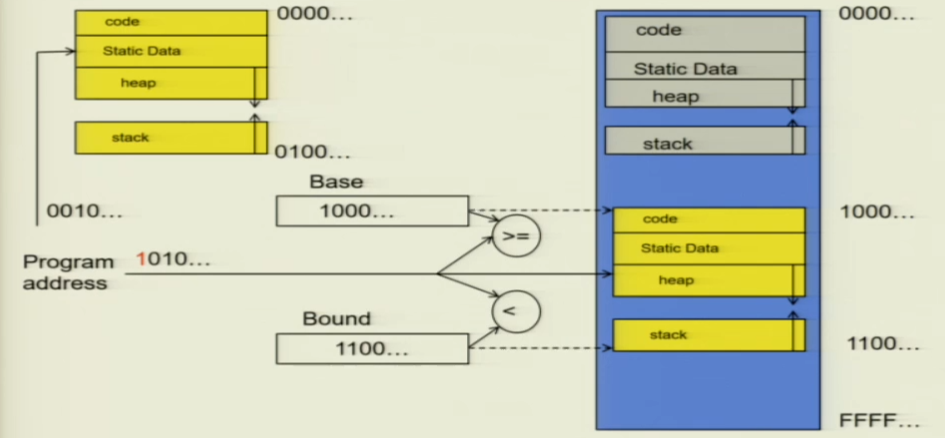
There are two registers in place: a base register and a bound register. These registers keep track of the specific memory segment accessible to the yellow thread. As the program initiates, the file from the disk is loaded and placed into this designated memory section. Consequently, during program execution, it operates in conjunction with the program counter. The hardware rapidly checks if the program counter is within the range of the base and bound.
However, if the yellow code section has a legal jump, such as a piece of code that makes the PC jump to 0001, this will break the OS section. As a result, we need to use address translation.
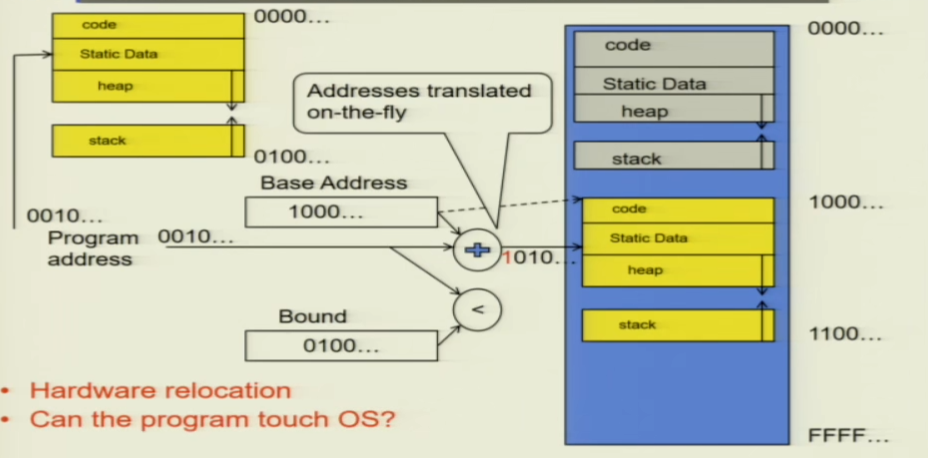
We can add a hardware adder. The address is actually dynamically converted, and all addresses are actually an offset. The operating system records the base address of each process, and then adds this offset to get the actual physical memory address.
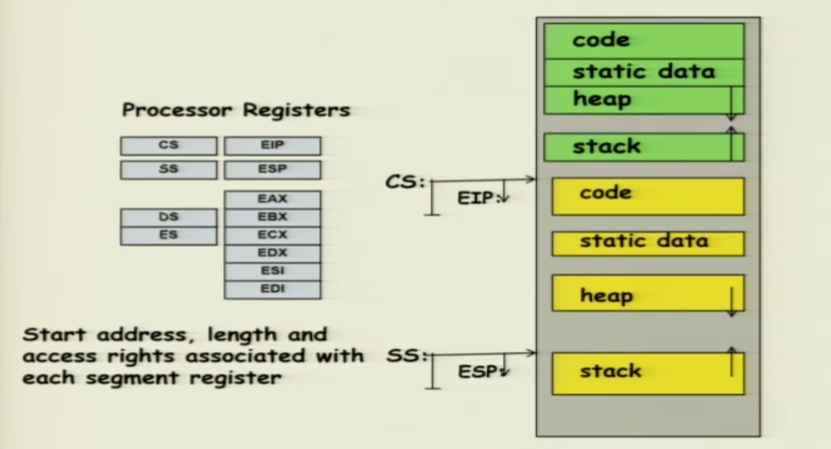
Another method is to use segments. In x86 hardware, we have various segments, such as code segments, stack segments, etc., each with different bases and lengths, (different bases and bounds). The code segment has a physical starting point (base) and length (bound), and the actual instruction pointer that runs is the offset within the segment.
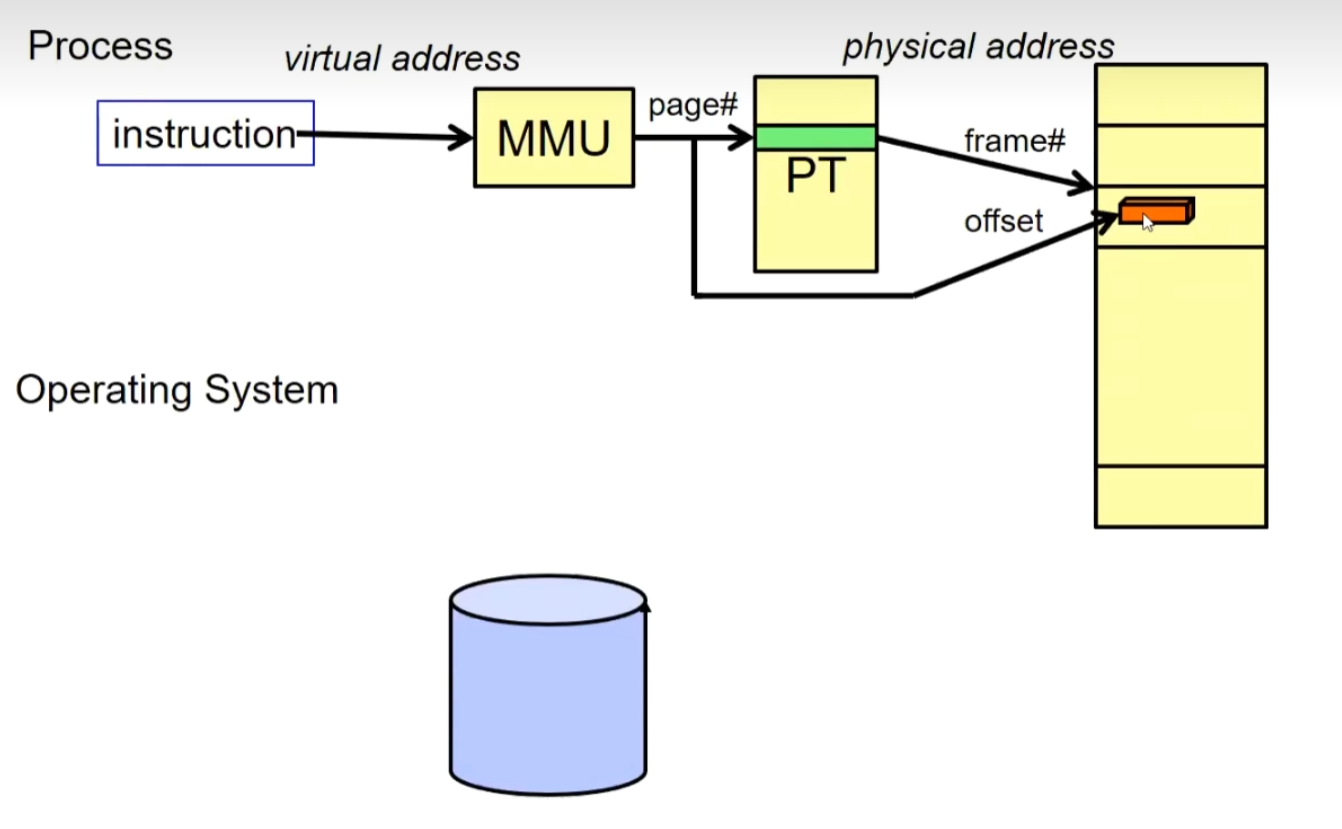
The last one is that we use more often in practice. We divide the address space(all DRAMs), into a bunch of pages of equal size (Page). The hardware will use the page table (Page Table) to convert from the virtual memory address to the DRAM’s memory address.
The processor has a virtual address, some are page numbers, and some are offsets. We need to take the page number to find the page we need. Find the corresponding memory address, and then use the offset to find the data.
Address Space
Address space => the set of accessible addresses+state associated with them
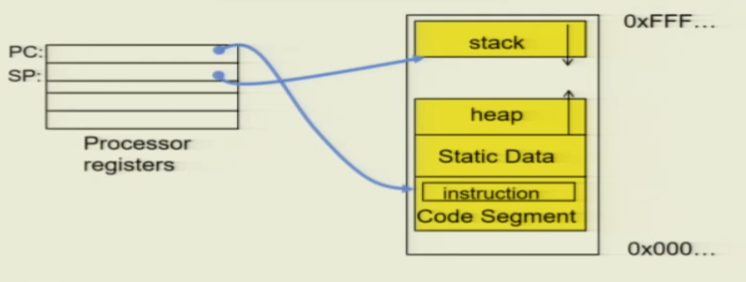
The Program Counter (PC) points to a specific address, which means the processor can execute the instruction located at that address.
The Stack Pointer (SP) points to a specific address, typically the bottom of the stack (in the diagram, the stack grows downward, so the last element is at the stack’s bottom).
Stack: When you recursively call a function, the variables of the previous function are pushed onto the stack, and then the stack pointer moves downward. When the function returns, you pop them out of the stack, and the stack pointer moves upward.
Heap: When you allocate memory using malloc() and similar functions, it is usually placed on the heap. The initial physical memory of the heap is typically less than what the program ultimately needs. As the program grows, things will be allocated on the heap, and you might encounter page faults, and then actual physical memory will be allocated.
Code Segment: It holds the code to be executed.
Static Data: Refers to static variables, global variables, and so on.
Virtual Address Space => Processor’s view of memory:
- Address Space is independent of physical storage
Process
Process: execution environment with Restricted Rights
(Protected) Address Space with One or More ThreadsOwns memory (address space)
Owns file descriptors, file system context, …
Encapsulate one or more threads sharing process resources
Application program executes as a process- Complex applications can fork/exec child processes
Why we need processes?
Protected from each other!
OS Protected from them
Processes provides memory protection
Threads more efficient than processes for parallelism
Fundamental tradeoff between protection and efficiency
Communication easier within a process
Communication harder between processes
Bootstrapping
First process is started by the kernel
Often configured as an argument to the kernel before the kernel boots
Often called the“init” process
After this, all processes on the system are created by other processes
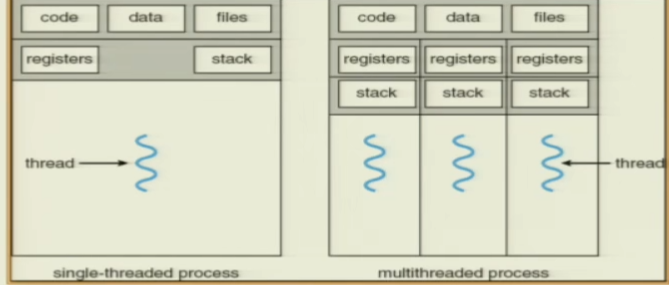
For single-threaded processes, there is only one set of registers and stack memory. For multi-threaded processes, the code segment, data, and files are shared, but each thread has its own set of registers and stack.However,they share the same portion of the address space.
Communication Between Processes
Process Abstraction Designed to Discourage lnter-Process Communication. So, must do something special (and agreed upon by both processes)
A simple option: use a file.

Shared Memory:
In-Memory Queue(Unix-pipe):

Here are two problems:
A generates data faster than B can consume it
B consumes data faster than A can produce it
We can solve them by WAITING:
If producer (A) tries to write when buffer full, it blocks (Put sleep until space)
If consumer (B) tries to read when buffer empty, it blocks (Put to sleep until data)
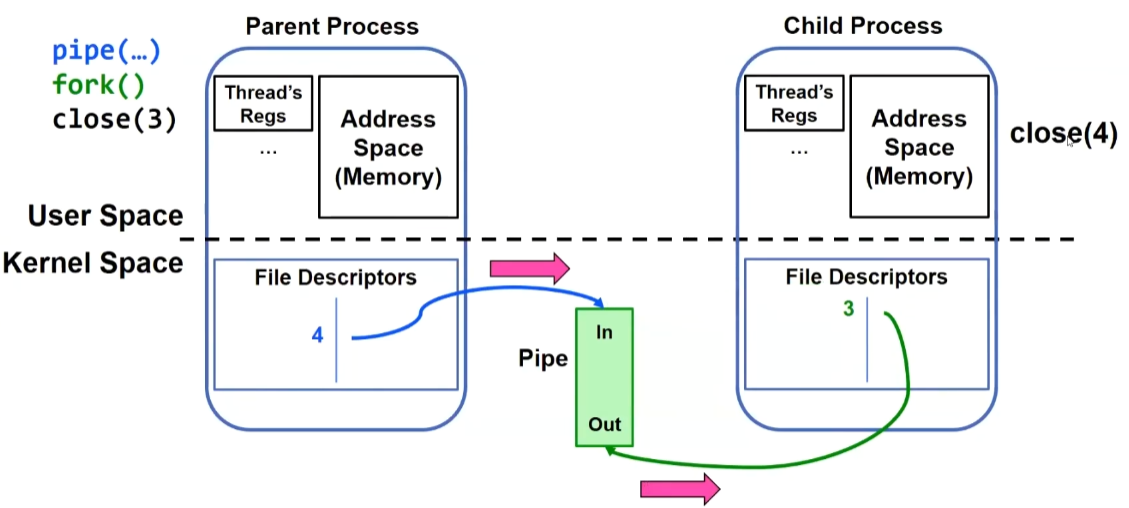
This is an example of communication between a parent process and a child process:
Multiplexing Processes
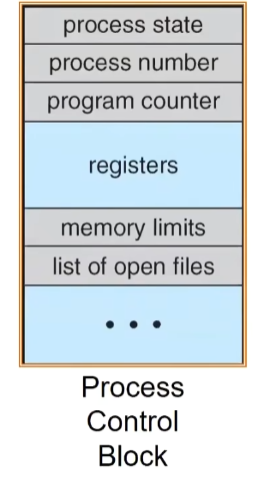
Kernel represents each process as a processcontrol block(PCB)
Status (running, ready, blocked, …)
Register state (when not ready)
Process ID (PID), User, Executable, Priority, …
Execution time,…
Memory space, translation, …
Context Switch
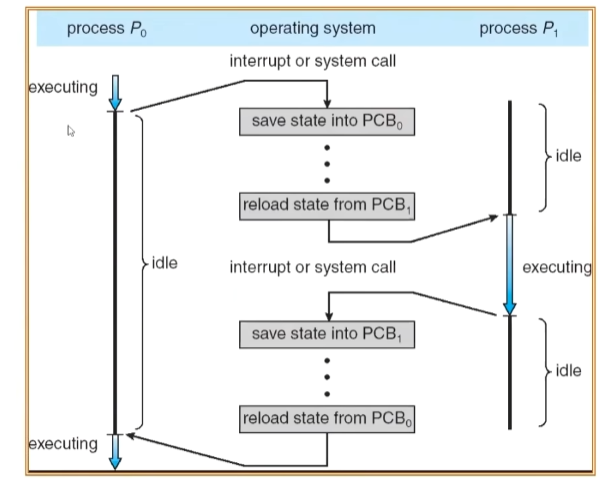
Bad Design:The idle time is greater than the execution time
Lifecycle of a Process or Thread
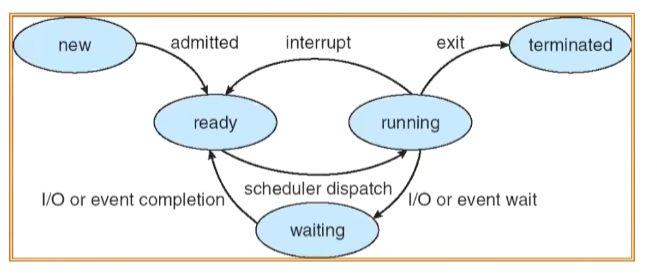
As a process executes, it changes state:
new: The process/thread is being created
ready: The process is waiting to run
running: Instructions are being executed
waiting: Process waiting for some event to occur
terminated: The process has finished execution
Why are we not possible to free the process up, but we keep it in a terminated state laying around ?
The parent process needs to obtain the execution result.
Dual Mode Operation
Hardware provides at least two modes:
1.Kernel Mode(or “supervisor” / “protected” mode)
2.User Mode
Certain operations are prohibited when running in usermode
- Changing the page table pointer
Carefully controlled transitions between user mode andkernel mode
- System calls,interrupts, exceptions
Unix System Structure
1 | User Mode Applications (the users) |
Kernel Mode is that code that gets 100% access to everything
User mode is that protected environment and that’s virtualized in some way
There are three possible types of operations that can trigger a transition from user mode to kernel mode:
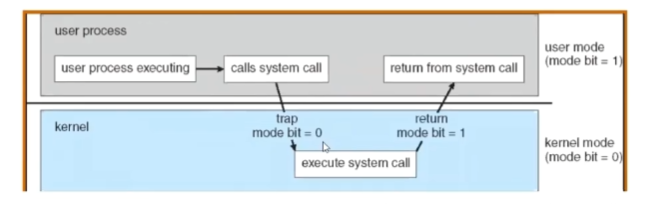
Syscall
Process requests a system service, e.g., exit
Like a function call, but in “outside” of the process
Does not have the address of the system function to call
Like a Remote Procedure Call (RPC)
Marshall the syscall id and args in registers and exec syscall
Interrupt
External asynchronous event triggers context switch
e.g., Timer, l/0 device
Independent of user process
Trap or Exception
Internal synchronous event in process triggers context switch
e.g., Protection violation (segmentation fault), Divide by zero, …
Files and I/O
File
Named collection of data in a file system
POSIX File data: sequence of bytes
- Could be text, binary, serialized objects,…
File Metadata: information about the file
- Size, Modification Time, Owner, Security info, Access control
Directory
“Folder”containing files & directories
Hierachical (graphical) naming
Path through the directory graph
Uniquely identifies a file or directory
- /home/ff/cs162/public html/fa14/index.html
Links and Volumes (later)
Every process has a current working directory(CWD), but absolute paths ignore CWD
Stream is an unformatted sequences of bytes, with a position
Key Unix I/O Design Concepts
Uniformity - everything is a file
file operations, device l/0, and interprocess communication through open, read/write,close
Allows simple composition of programs
Open before use
Provides opportunity for access control and arbitration
Sets up the underlying machinery, i.e., data structures
Byte-oriented
- Even if blocks are transferred, addressing is in bytes
Kernel buffered reads
Streaming and block devices looks the same, read blocks yielding processor to other task
Kernel buffered writes
- Completion of out-going transfer decoupled from the application, allowing it tocontihue
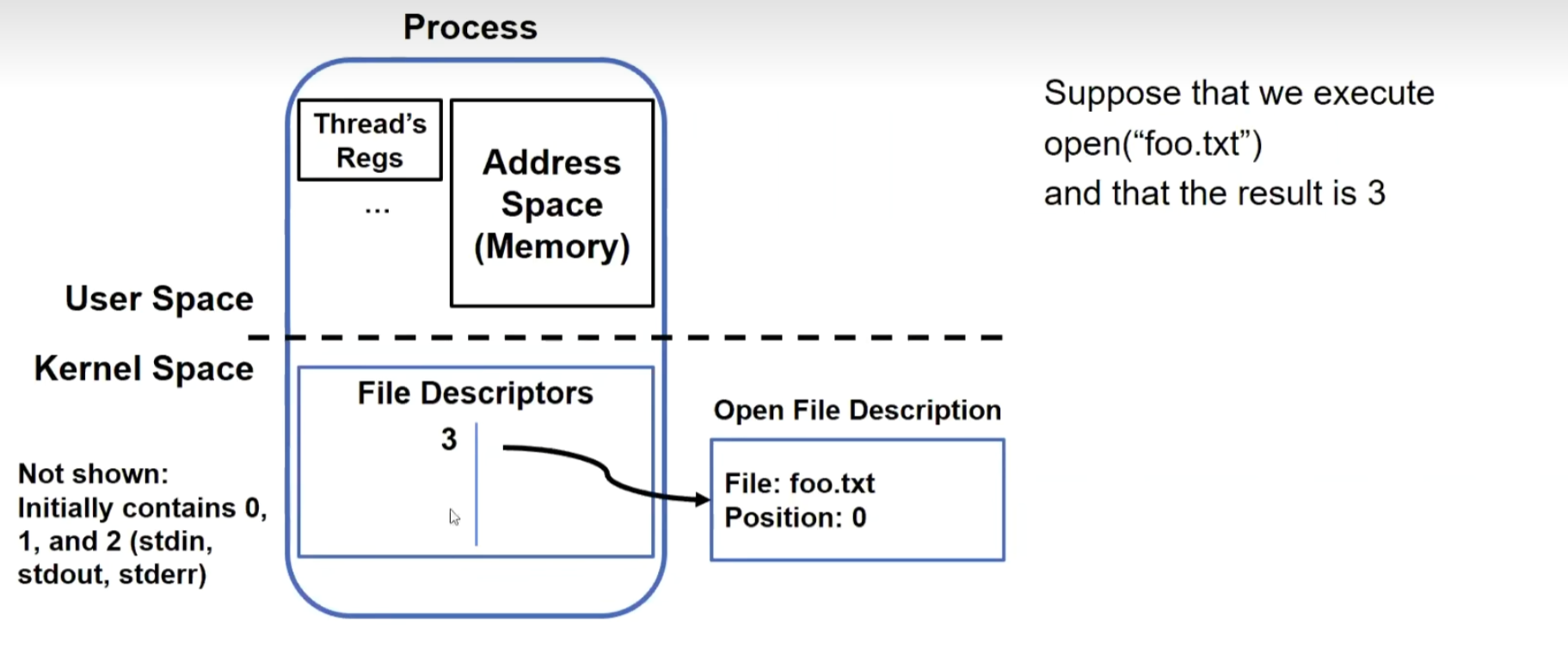
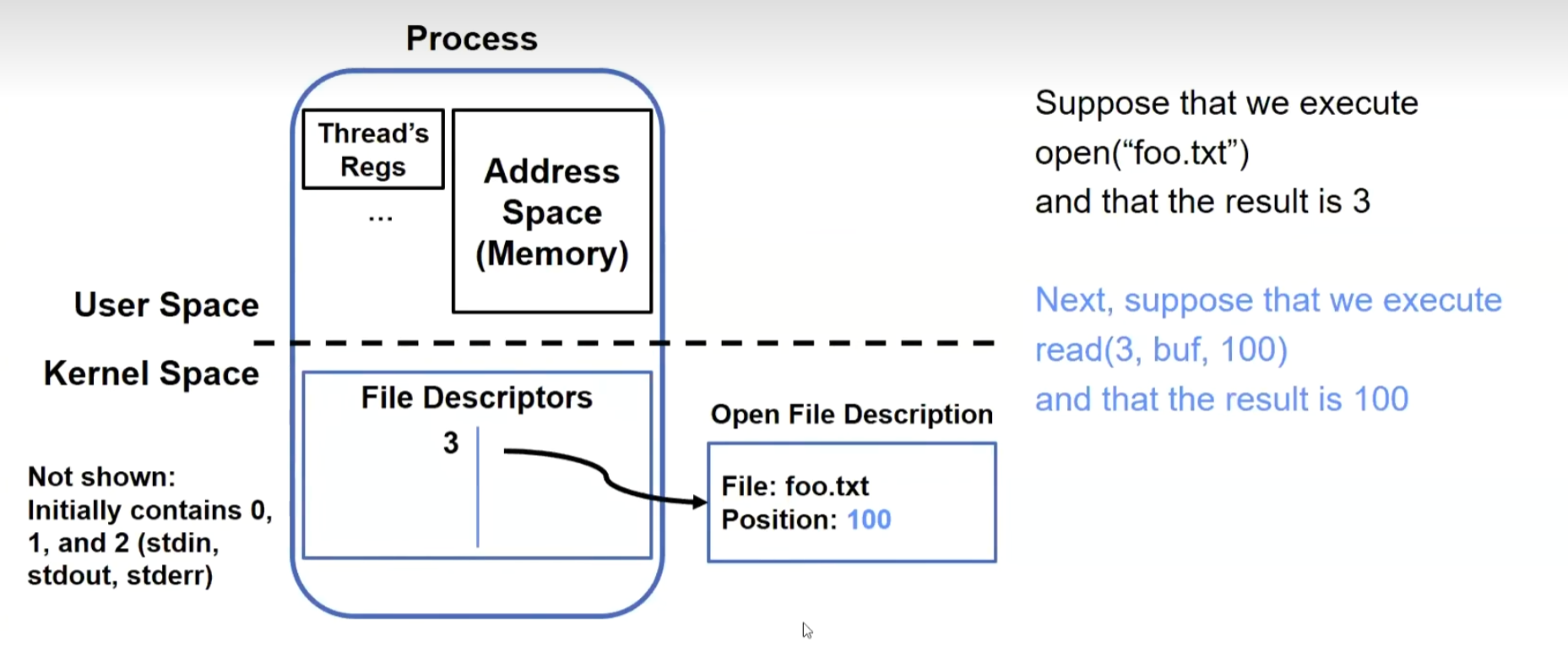
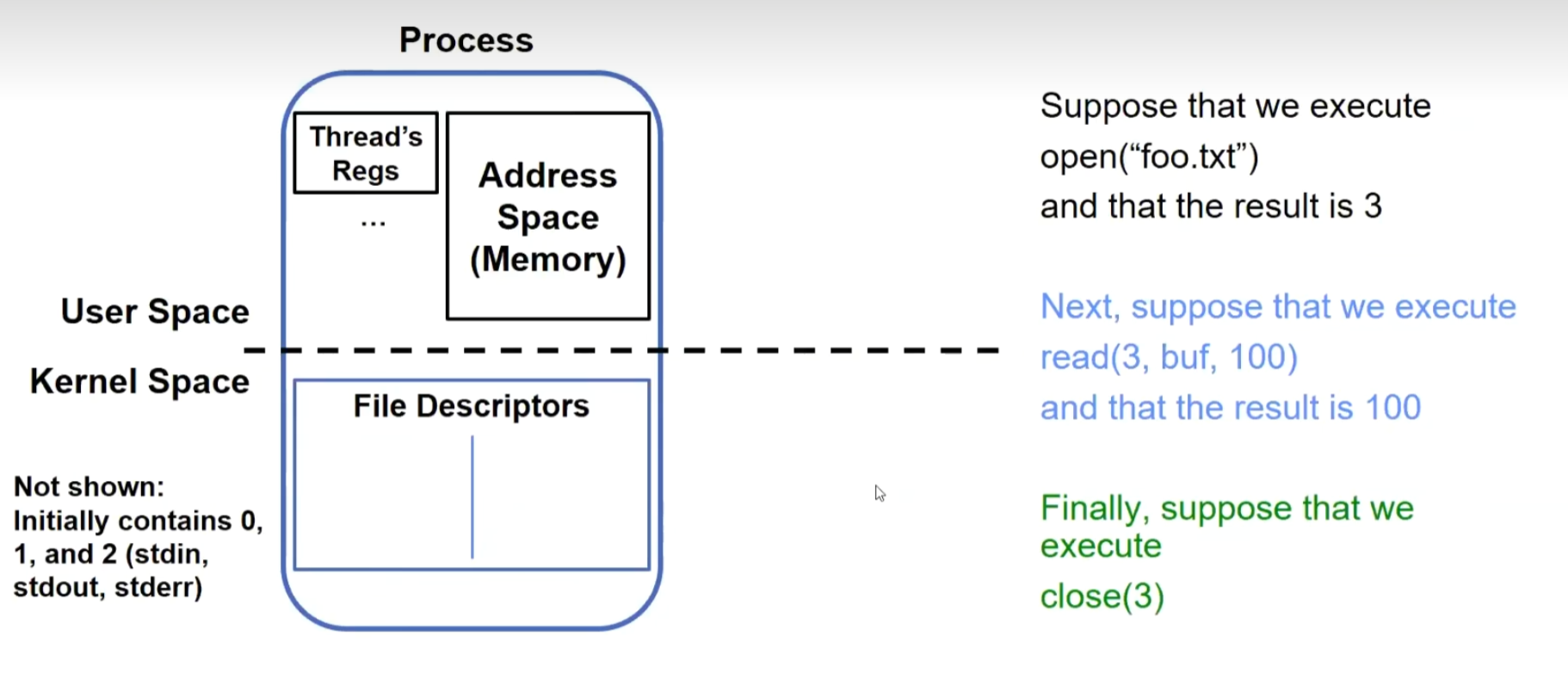
File Descriptors
The reason why a file descriptor is represented as a number:
File descriptor entries reside within the kernel and are inaccessible to users.
Users can only manipulate this number in the subsequent operations, ensuring that they cannot access unauthorized resources. The kernel uses an internal table to validate this number, and if there’s no match, no operation will be performed.
Files within a process:
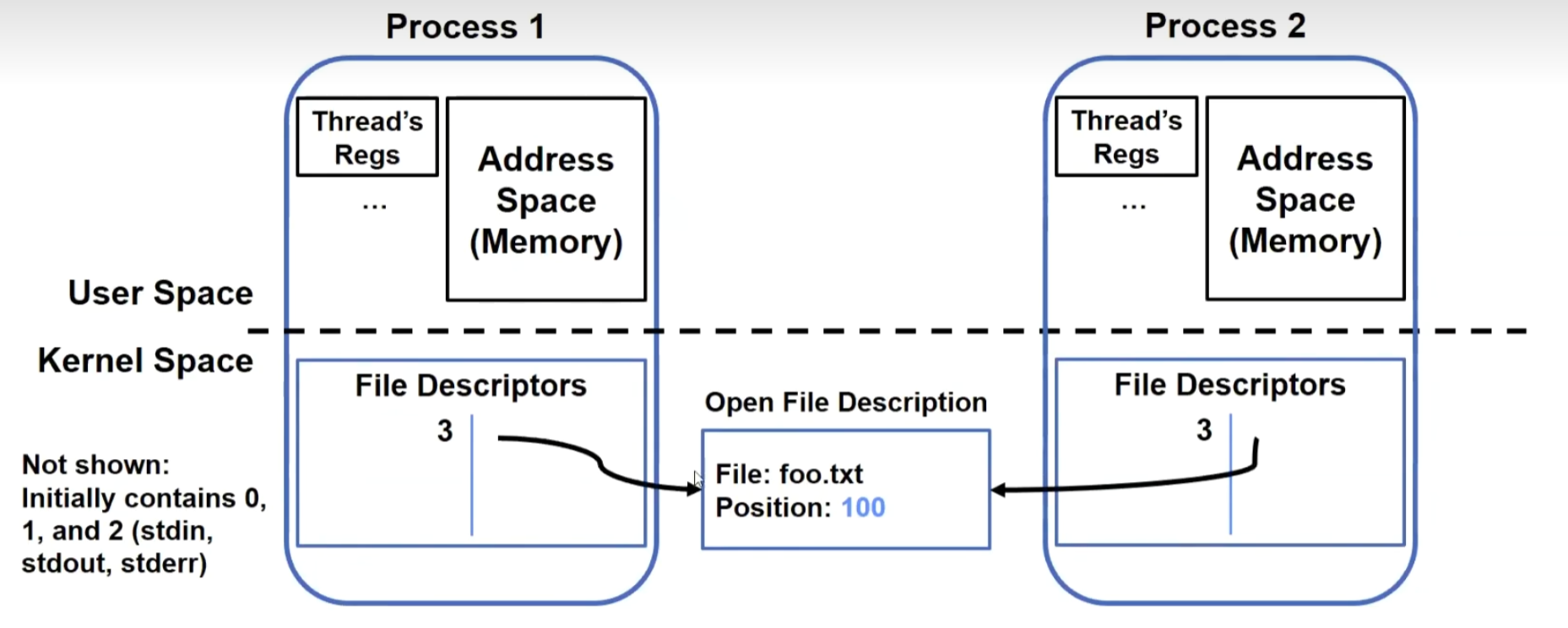
Instead of closing, let’s fork():
Semaphores and Lock
Lock
Lock: prevents someone from doing something
Lock before entering critical section and before accessing shared data
Unlock when leaving, after accessing shared data- Wait if locked
- Important idea: all synchronization involves waiting
Locks provide two atomic operations:
acquire(&mylock) - wait until lock is free; then mark it as busy
- After this returns, we say the calling thread holds the lock
release(&mylock) - mark lock as free
Should only be called by a thread that currently holds the lock
After this returns, the calling thread no longer holds the lock
Here is a Producer-Consumer with a Bounded BUffer problem
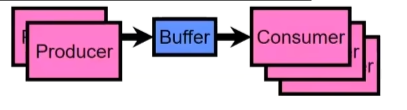
Problem Definition
Producer(s) put things into a shared buffer
Consumer(s) take them out
Need synchronization to coordinate producer/consumer
Solution
1 | Producer(item){ |
However, this really is wasting a whole bunch of cpu time
Implementation
Interrupts
1 | LockAcquire() { |
We have two problems:
Users must not control interrupts
The execution time of critical sections should remain uncontrollable; therefore, this could potentially result in the system being stuck in a single thread for an extended period of time.
Better Implementation:
Key idea: maintain a lock variable and impose mutual exclusion only during operations on that variable
1 | int value = FREE; |
Why do we need to disable interrupts at all?
Avoid interruption between checking and setting lock value
Otherwise two threads could think that they both have lock
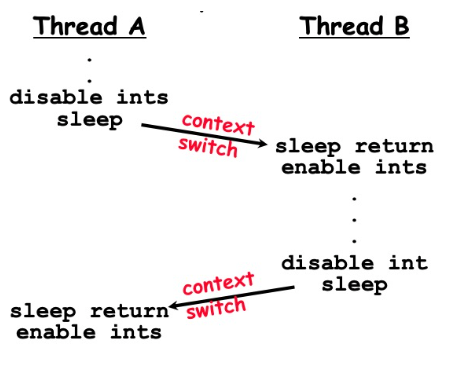
Additionally, in the aforementioned solution, we also need to enable interrupts during the process of Acquire failure; otherwise, other processes will be unable to call Acquire or Release. We can choose from the following three positions to initiate this, but none of them can resolve the issue.

Position 1: Before putting the thread onto the wait queue, causing the wakeUp signal to not be received.
Position 2: The thread might be woken up before going to sleep.
Position 3: The thread is already asleep, and the program can’t reach this position before sleeping.
The correct approach is to delegate the responsibility of enabling interrupts to the next scheduled thread:
The flaw in using interrupts to implement locks lies in:
The inability to accomplish Acquire and Release at the user-level.
In a multiprocessor environment, enabling interrupts needs to be performed on multiple processors, which adds extra communication overhead.
Atomic Read-Modify-Write Instructions
These instructions read a value and write a new value atomically
Hardware is responsible for implementing this correctly
- on both uniprocessors (not too hard)》and multiprocessors (requires help from cache coherence protocol)
Unlike disabling interrupts, can be used on both uniprocessors and multiprocessors
for example:
1 | test&set (&address) { /* most architecture */ |
Implementing Locks With test&set:
1 | int value = 0; |
Simple explanation:
If lock is free, test&set reads 0 and sets lock=1, so lock is now busylt returns 0 so while exits.
If lock is busy, test&set reads 1 and sets lock=1 (no change)lt returns 1, so while loop continues.
When we set the lock = 0, someone else can get lock.
Pros
No need to use interrupts; the normal functioning of interrupts remains unaffected.
User code can utilize this lock without entering kernel mode.
It can be used on multi-core machines.
Cons
busy-waiting, inefficient
waiting thread may take cycles away from thread
priority inversion: if busy-waiting thread has higher priority than thread holding lock => no progress
Improvement
1 | int guard = 0; |
Semaphores
Semaphores are a kind of generalized lock
Definition: a Semaphore has a non-negative integer value and supportsthe following two operations:
P() or down( ): atomic operation that waits for semaphore to becomepositive, then decrements it by 1
V() or up( ): an atomic operation that increments the semaphore by 1.waking up a waiting P, if any
Semaphores are like integers, except:
No negative values
Only operations allowed are P and V - can’t read or write value, except initially
Operations must be atomic
Two P’s together can’t decrement value below zero
Thread going to sleep in P won’t miss wakeup from V - even if both happen at same time
Producer-Consumer with a Bounded BUffer problem’s solution
1 | Semaphore fullSlots = 0;// Initially,no coke |
Monitor
Semaphores can be used for both Mutual Exclusion and Scheduling Constraints. This design can sometimes confuse users and goes against the philosophy of “Do one thing and do it well”; this is also the purpose for which Monitors were introduced:Use locks for mutual exclusion and condition variables for scheduling constraints
A Monitor consists of two parts:
A Lock
Used to protect shared data.
Must be locked before accessing shared data.
Must be unlocked after finishing the use of shared data.
Initially free.
Zero or more condition variables
Condition Variable
A queue of threads waiting for something inside acritical section
Key idea: allow sleeping inside critical section by atomically releasing lock attime we go to sleep
Contrast to semaphores: Can’t wait inside critical section
Operations
Wait(&lock): Atomically release lock and go to sleep Re-acquire lock later, before returning
Signal(): Wake up one waiter, if any
Broadcast():Wake up all waiters
Hoare monitors
Signaler gives up lock, CPU to waiter; waiter runs immediately
Then, Waiter gives up lock, processor back to signaler when it exitscritical section or if it waits again
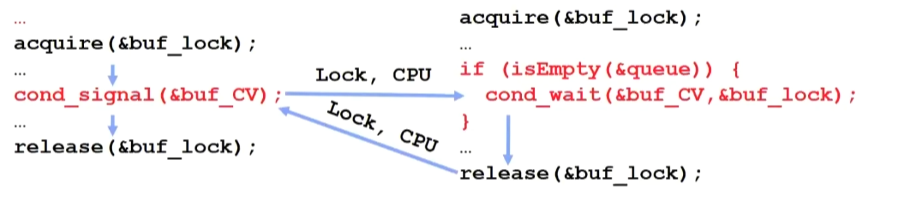
On first glance, this seems like good semantics
- Waiter gets to run immediately, condition is still correct!
Most textbooks talk about Hoare scheduling
However, hard to do, not really necessary!
Forces a lot of context switching (inefficient!)
Mesa monitors
Signaler keeps lock and processor
Waiter placed on ready queue with no special priority
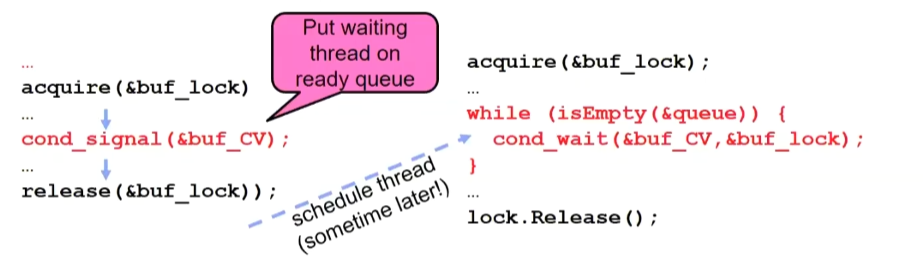
Practically, need to check condition again after wait
- By the time the waiter gets scheduled, condition may be false again - so, just check again with the “while” loop
Most real operating systems do this!
- More efficient,easier to implement Signaler’s cache state, etc still good
Two Examples
Producer-Consumer with a Bounded BUffer problem’s solution
1 | lock buf_lock = <initially unlocked> |
Readers/Writers Problem
Motivation: Consider a shared database
Two classes of users:
Readers --never modify database
Writers --read and modify database
Correctness Constraints:
Readers can access database when no writers
Writers can access database when no readers or writers
Only one thread manipulates state variables at a time
State variables:
AR: Number of active readers; initially = 0
WR: Number of waiting readers; initially = 0
AW: Number of active writers; initially = 0
WW: Number of waiting writers; initially = 0
Condition: okToRead = NIL
Condition: okToWrite = NIL
1 | Reader() { |
Concurrency
The Core of Concurrency: the Dispatch Loop
1 | Loop { |
Running a Thread
Load its state (registers, PC, stack pointer) into CPU
Load environment (virtual memory space, etc)
Jump to the PC
Both the operating system that manages threads and the threads themselves run on the same CPU. We need to ensure that we can perform appropriate switching between them.
How does the operating system regain control of the CPU ?
Internal events: thread returns control voluntarily
External events: thread gets preempted
Internal events
Blocking on I/0
- The act of requesting l/0 implicitly yields the CPU
Waiting on a “signal” from other thread
- Thread asks to wait and thus yields the CPU
Thread executes a yield()
- Thread volunteers to give up CPU
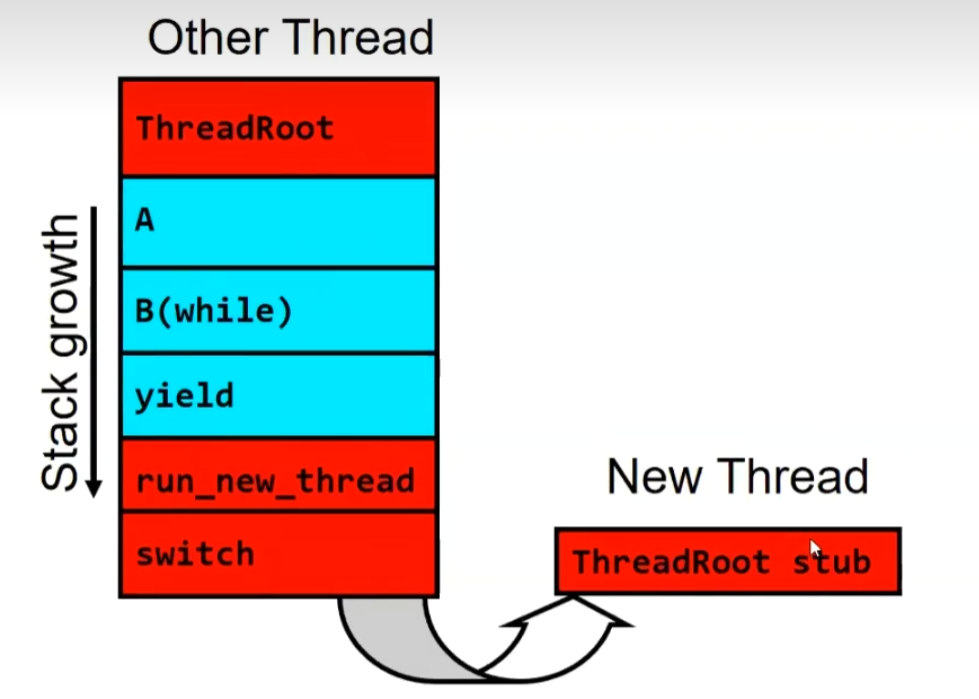
Stack for Yielding Thread
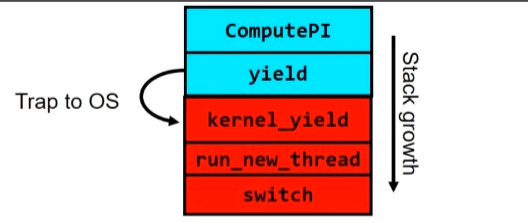
1 | run new thread() { |
the Stacks Look Like:
The reasons are as follows: First, abstracting the switch().
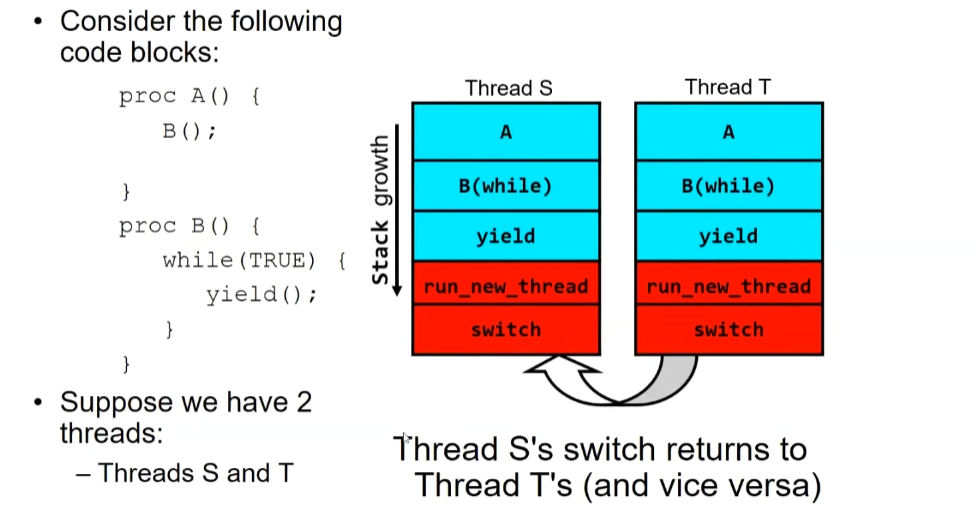
1 | switch(Thread A,ThreadB){ |
When Thread S reaches the switch(), save the information of S and load the information of T. At this point, the stack pointer of S remains at the return within the switch. Subsequently, when Thread T reaches the switch() , save the information of T and load the information of S. At this moment, the stack pointer of S is positioned at the return within the switch, and execution continues. The return operation requires popping the stack. Stack popping continues until B (while) is re-executed.
What happens when thread blocks on I/O?
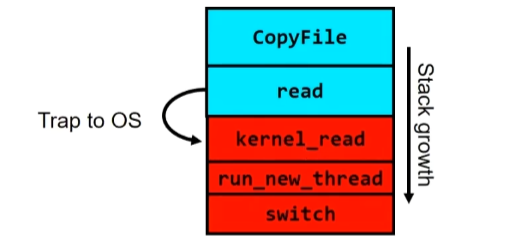
User code invokes a system call
Read operation is initiated
Run new thread/switch
External Events
What happens if thread never does any I/O, never waits, and never yields control ?
Answer: utilize external events
Interrupts: signals from hardware or software that stop the running code and jump to kernel
Timer: like an alarm clock that goes off every some milliseconds
Timer
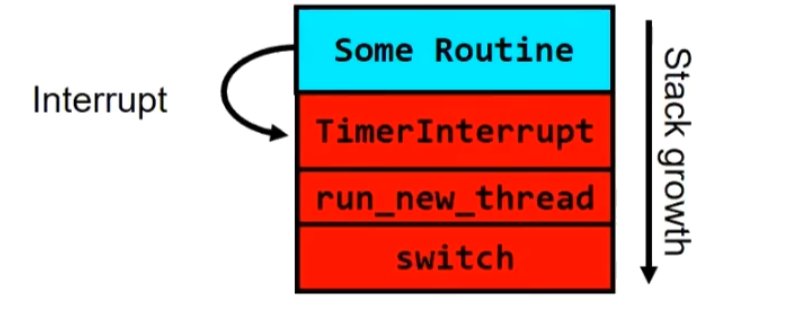
1 | TimerInterrupt() { |
How do we initialize TCB and Stack?
Initialize Register fields of TCB
Stack pointer made to point at stack
PC return address => OS(asm) routine ThreadRoot()
Two arg registers (a0 and a1) initialized to fcnPtr and fcnArgPtr,respectively
Initialize stack data?
No. Important part of stack frame is in registers (ra)
Think of stack frame as just before body of ThreadRoot() really gets started
How does Thread get started?
After invoking ‘run_new_thread’, the ‘dispatcher switch’ to ThreadRoot, which serves as the starting point for thread execution:
1 | ThreadRoot(fcnPtr, fcnArgPtr) { |
How do we make a new thread?
Setup TCB/kernel thread to point at new user stack and ThreadRoot code
Put pointers to start function and args in registers
This depends heavily on the calling convention
Atomic Operations
For the following case:(y=12)
1 | Thread A Thread B |
In this case, the value of x is not fixed. It is possible that Thread B switches to Thread A after setting y=2, or Thread B might complete its execution before Thread A starts. We can resolve this using atomic operations.
Definition
An operation that always runs to completion or not at all
It is indivisible: it cannot be stopped in the middle and state cannot be modified by someone else in the middle
Fundamental building block - if no atomic operations, then have no way for threads to work together
Synchronization And Mutual Exclusion
Synchronization: using atomic operations to ensure cooperation between threadsFor now, only loads and stores are atomic- We are going to show that its hard to build anything useful with only reads and writes
Mutual Exclusion: ensuring that only one thread does a particular thing at a time- One thread excludes the other while doing its task
Critical Section: piece of code that only one thread can execute at once. Only onethread at a time will get into this section of code- Critical section is the result of mutual exclusion- Critical section and mutual exclusion are two ways of describing the same thing
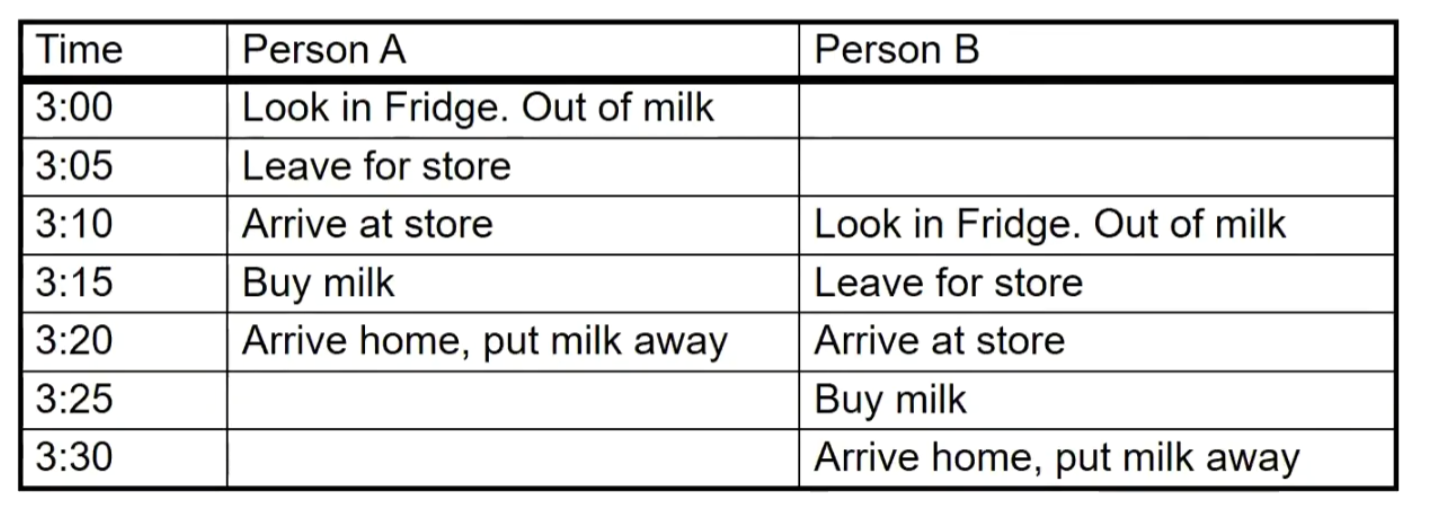
Too Much Milk Problem
Assuming you and your roommate share a refrigerator, which contains milk. Both you and your roommate go to the supermarket to buy milk and put it in the fridge when you notice there is no milk. In this scenario, the following events may occur:
The solution to this problem should achieve the following:
Never more than 1 person buys
Someone buys if needed
Use a note to avoid buying too much milk:
Leave a note before buying (kind of “lock”)
Remove note after buying (kind of “unlock”)
Don’t buy if note (wait)
Solution #1
1 | if (noMilk) { |
However, this situation may arise:Occasionally, an excessive amount of milk may be purchased.
1 | Thread A Thread B |
Solution #2
1 | Thread A Thread B |
Possible for neither thread to buy milk
- Context switches at exactly the wrong times can lead each to think thatthe other is going to buy
Solution #3
1 | Thread A Thread B |
At X:
If no note B, safe for A to buy.
Otherwise wait to find out what will happen
At Y:
If no note A, safe for B to buy
Otherwise, A is either buying or waiting for B to quit
Solution #3 works, but it’s really unsatisfactory
Really complex - even for this simple an example
- Hard to convince yourself that this really works
A’s code is different from B’s - what if lots of threads?
- Code would have to be slightly different for each thread
While A is waiting, it is consuming CPU time
- This is called “busy-waiting
Solution #4
using Lock
1 | milklock.Acquire(); |
Scheduling
Deciding which threads are given access to resources from moment to moment
Scheduling Policy Goals/Criteria
Minimize Response Time
Minimize elapsed time to do an operation (or job)
Response time is what the user sees
Time to echo a keystroke in editor
Time to compile a program
Real-time Tasks: Must meet deadlines imposed by World
Maximize Throughput
Maximize operations (or jobs) per second
Minimizing response time will lead to more context switching than if you only maximized throughput
Two parts to maximizing throughput
Minimize overhead (for example: context-switching)
Efficient use of resources (CPU, disk, memory, etc)
Fairness
Share CPU among users in some equitable way
Fairness is not minimizing average response time
The above are the main objectives of the Scheduling Policy, but there is a clear trade-off among these three objectives:
Minimizing Response Time increases the frequency of context switches and also raises the cache miss rate, leading to a decrease in CPU utilization, which contradicts the goal of Maximizing Throughput.
Minimizing Response Time prioritizes short tasks over long tasks, which contradicts Fairness.
Fairness aims to distribute resources fairly among threads, which increases the frequency of context switches and cache miss rate, resulting in a decrease in CPU utilization, contradicting the goal of Maximizing Throughput.
Scheduling Policies
First-Come, First-Served (FCFS) Scheduling
for example:
| Process | Burst Time |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
Gantt Chart:

Waiting time for P1 = 0; P2 = 24; P3 = 27
Average waiting time: (0 + 24 + 27)/3 = 17
Average Completion time: (24 + 27 + 30)/3 = 27
As we can see, from the perspective of Average Waiting Time and Completion Time, the earlier long task is dragging down the performance, a phenomenon known as the Convoy Effect.
FIFO Pros and Cons:
Simple
Short jobs get stuck behind long ones
Round Robin (RR)
FCFS is not particularly favorable for short-duration tasks. The scheduling outcome varies based on the order of task submissions. If a long-duration task happens to start just before a short-duration task, that short-duration task certainly doesn’t feel comfortable about it.
Round Robin Scheme: Preemption!
Each process gets a small unit of CPU time(time quantum), usually 10-100 milliseconds
After quantum expires, the process is preemptedand added to the end of the ready queue.
n processes in ready queue and time quantum is q =>
Each process gets 1/n of the CPU time
In chunks of at most q time units
No process waits more than (n-1)q time units
Performance
q large => FCFS
q small => Interleaved (really small => hyperthreading?)
q must be large with respect to context switch, otherwise overhead is too high (all overhead)
for example(q=20)
| Process | Burst Time |
|---|---|
| P1 | 53 |
| P2 | 8 |
| P3 | 68 |
| P3 | 24 |
Gantt Chart:

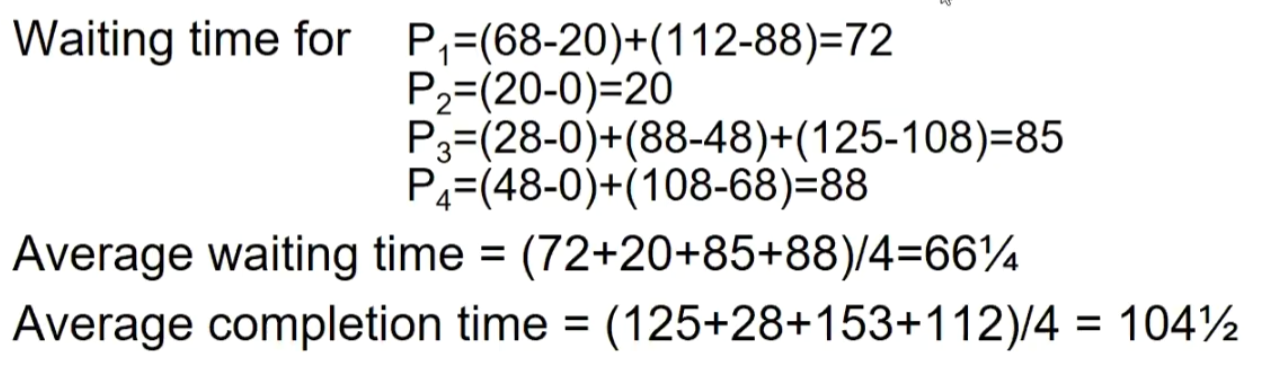
Round-Robin Pros and Cons
Better for short jobs, Fair (+)
Context-switching time add up for long jobs
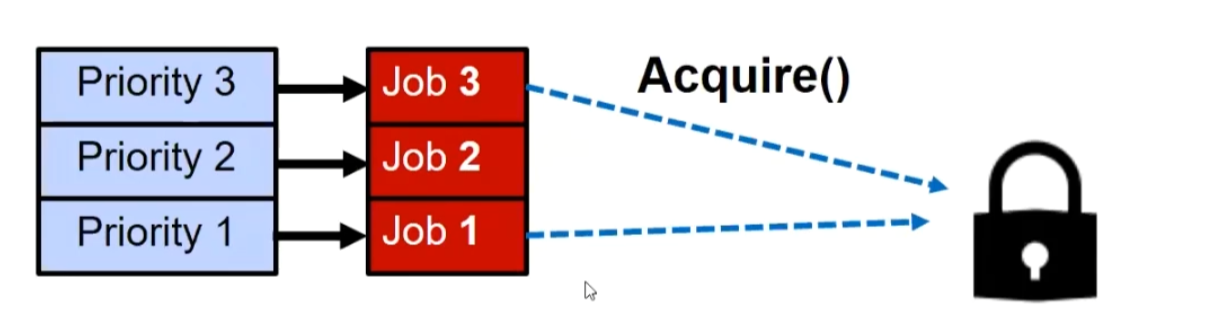
Strict Priority Scheduling
Each process is assigned an importance level, and tasks belonging to the same level are placed in the same queue. Tasks within the queue are scheduled using the FCFS|RR. Only after all higher-priority tasks have been completed can lower-priority tasks be executed. The problem with this approach is that:
Starvation: Low-priority tasks may experience starvation.
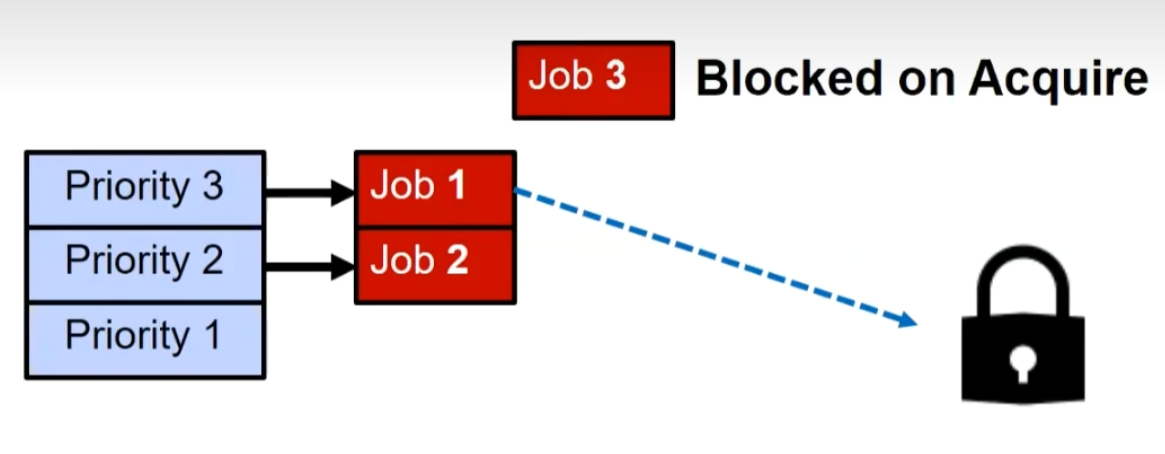
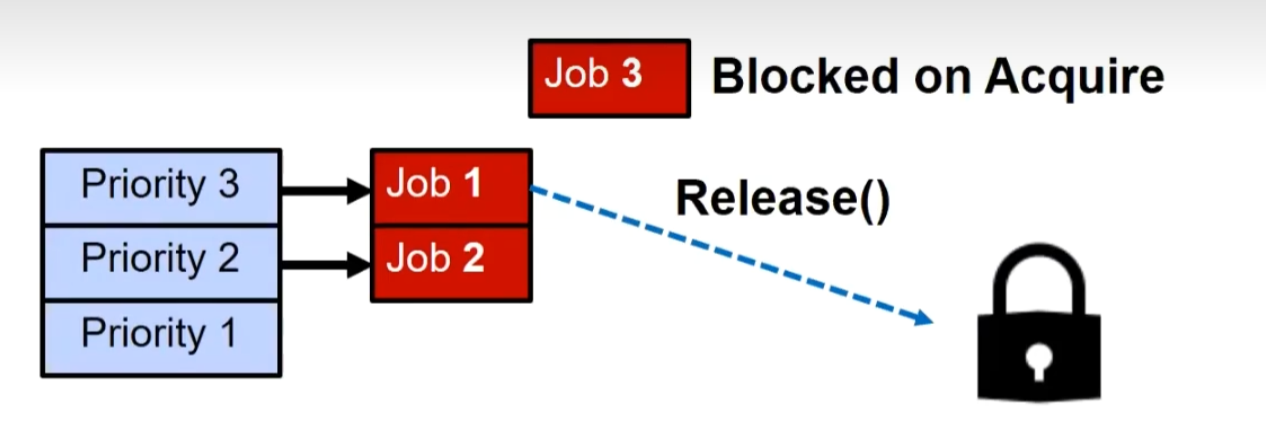
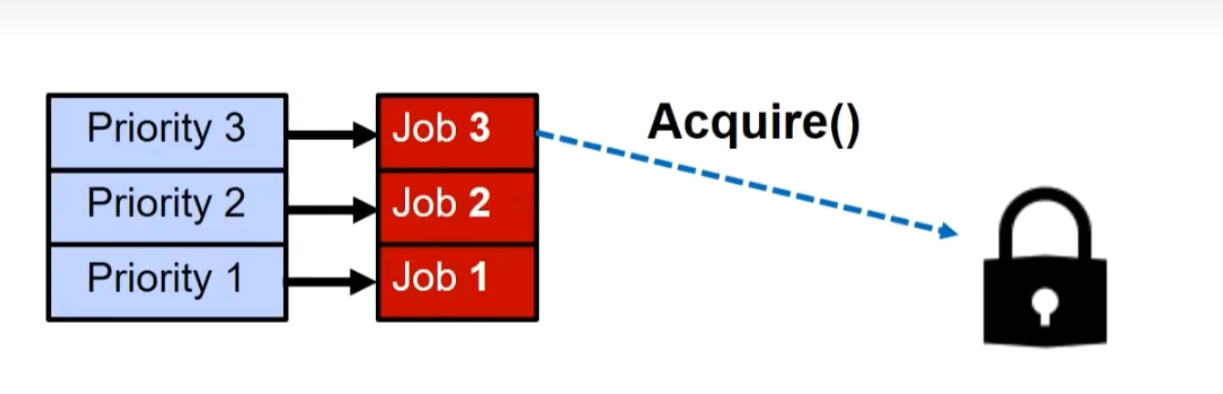
Priority Inversion
Where high priority task is blocked waiting on low priority task
Low priority one must run for high priority to make progress
Medium priority task can starve a high priority one
Solution: Priority Donation
What if we Knew the Future?
Shortest Job First (SJF)
Run whatever job has the least amount of computation to do
Sometimes called “Shortest Time to Completion First” (STCF)
Starvation
SRTF can lead to starvation if many small jobs!
Large jobs never get to run
Shortest Remaining Time First (SRTF)
Preemptive version of SJF: if job arrives and has a shorter time to completion than the remaining time on the current job, immediately preempt CPU
Sometimes called “Shortest Remaining Time to Completion First” (SRTCF)
Lottery Scheduling
Give each job some number of lottery tickets
On each time slice, randomly pick a winning ticket
On average, CPU time is proportional to number of ticketsgiven to each job
How to assign tickets?
To approximate SRTF, short running jobs get more, long running jobs get fewer
To avoid starvation, every job gets at least one ticket (everyone makesprogress)
Advantage over strict priority scheduling: behaves gracefully as load changes. Adding or deleting a job affects all jobs proportionally, independent of how many tickets each iob possesses
DeadLock
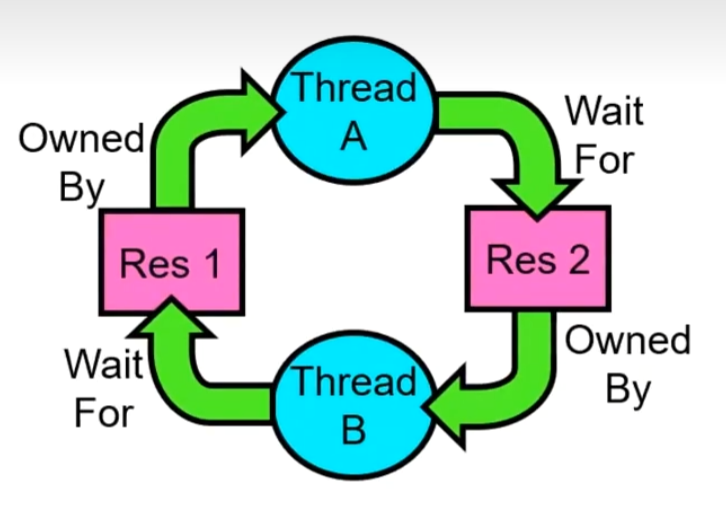
Deadlock: circular waiting for resources
- Thread A owns Res 1 and is waiting for Res 2
- Thread B owns Res 2 and is waiting for Res 1
Case Thread A & B
1 | Thread A: Thread B: |
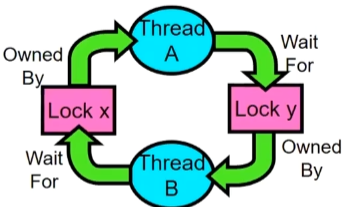
This lock pattern exhibits non-deterministic deadlock
- Sometimes it happens, sometimes it doesn’t!
Four Requirements for Deadlock
Mutual exclusion
- Only one thread at a time can use a resource
Hold and wait
- Thread holding at least one resource is waiting to acquire additionalresources held by other threads
No preemption
- Resources are released only voluntarily by the thread holding theresource, after thread is finished with it
Circular wait
- There exists a set {
} of waiting threads
Detecting DeadLock
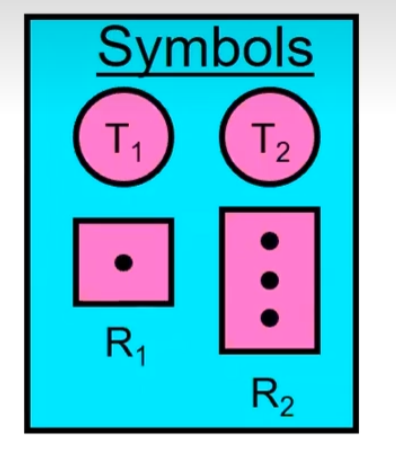
System Model
A set of Threads
Resource type
- CPU cycles, memory space,I/O devices
Each resource type
has instances Each thread utilizes a resource as follows:
- Request(), Use(), Release()
Resource-Allocation Graph
V is partitioned into two types:
T = {
} R = {
}
request edge - directed edge
assignment edge - directed edge
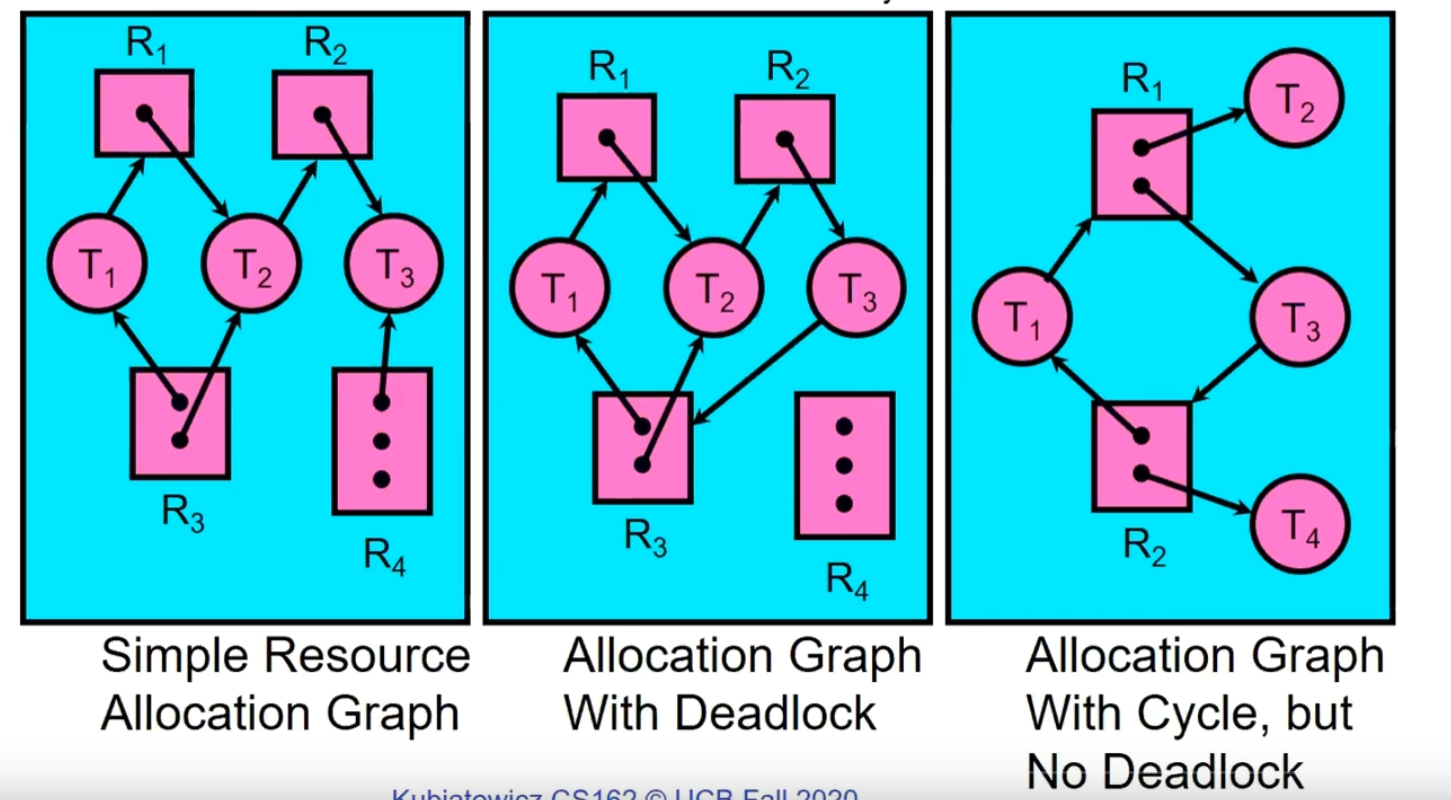
When there is only one instance of each resource, you can directly check if there is a cycle in the Resource-Allocation Graph. When there are multiple instances of each resource, simulation can be used to achieve this:
1 | [FreeResources]: Current free resources each type |
Nodes left in UNFINISHED => deadlocked
Deal with deadlock
Four different approaches:
Deadlock prevention: write your code in a way that it isn’t prone to deadlock
Deadlock recovery: let deadlock happen, and then figure out how to recover from it
Deadlock avoidance: dynamically delay resource requests so deadlock doesn’t happen
Deadlock denial: ignore the possibility of deadlock
DeadLock Avoidance
Idea: When a thread requests a resource, OS checks if it would result in unsafe state
If not, it grants the resource right away
If so, it waits for other threads to release resources
Three States:
Safe state
- System can delay resource acquisition to prevent deadlock
Unsafe state
No deadlock yet…
But threads can request resources in a pattern that unavoidably leads to deadlock
Deadlocked state
There exists a deadlock in the system
Also considered “unsafe”
Banker’s Algorithm
Toward right idea:
State maximum (max) resource needs in advance
Allow particular thread to proceed if:
(available resources - #requested)>= max remaining that might be needed by any thread
Banker’s algorithm (less conservative):
Allocate resources dynamically
- Evaluate each request and grant if some ordering of threads is still deadlock free afterward
Technique: pretend each request is granted, then run deadlock detection algorithm:
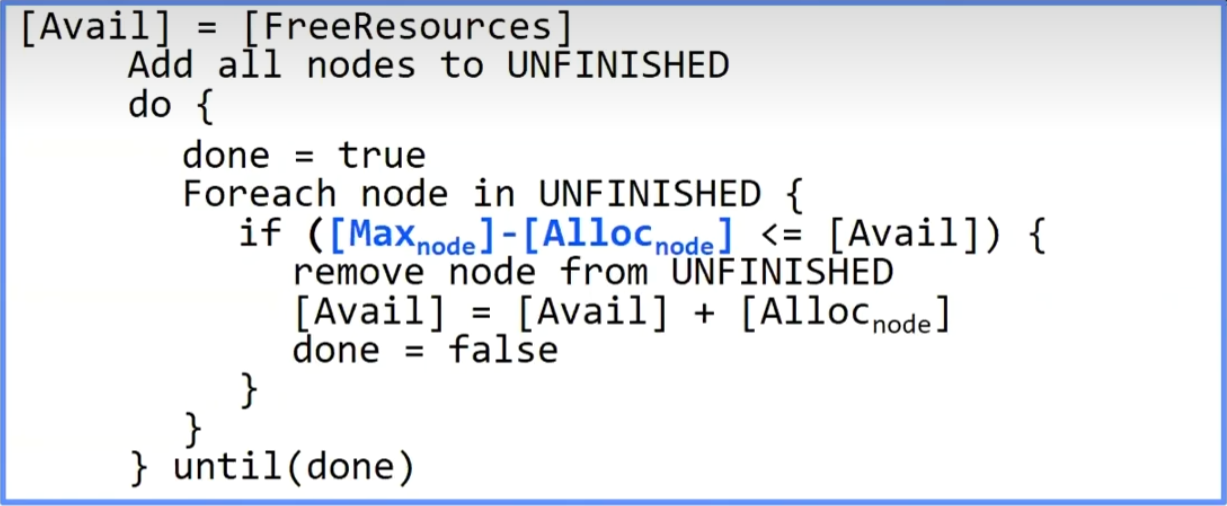
Keeps system in a “SAFE” state
Algorithm allows the sum of maximum resource needs of all current threads to be greater than total resources
Multi-Level Feedback Scheduling
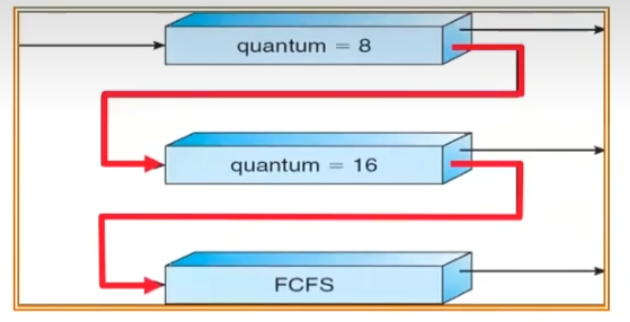
Another method for exploiting past behavior (first use in CTSS)
Multiple queues, each with different priority
- Higher priority queues often considered “foreground” tasks
Each queue has its own scheduling algorithm
e.g. foreground - RR, background - FCFS
Sometimes multiple RR priorities with quantum increasing exponentially(highest:1ms, next: 2ms, next: 4ms, etc)
Adjust each job’s priority as follows (details vary)
Job starts in highest priority queue
If timeout expires, drop one level
If timeout doesn’t expire,push up one level (or to top)
Countermeasure: user action that can foil intent of the OS designers
For multilevel feedback, put in a bunch of meaningless I/0 to keep job’spriority high
Of course, if everyone did this, wouldn’t work!
Case:Linux O(1) Scheduler

Priority-based scheduler: 140 priorities
40 for“user tasks(set by “nice”),100 for“Realtime/Kernel’
Lower priority value => higher priority (for nice values)
Highest priority value => Lower priority (for realtime values
All algorithms O(1)
Timeslices/priorities/interactivity credits all computed when job finishes time slice
140-bit bit mask indicates presence or absence of job at given priority level
Two separate priority queues:“active” and “expired”
- All tasks in the active queue use up their timeslices and get placed on the expiredqueue, after which queues swapped
Timeslice depends on priority - linearly mapped onto timeslice range
Like a multi-level queue (one queue per priority) with different timeslice at each level
Execution split into “Timeslice Granularity” chunks - round robin through priority
Heuristics
User-task priority adjusted +5 based on heuristics
p->sleep avg = sleep time - run time
Higher sleep avg => more l/0 bound the task, more reward (and vice versa)
Interactive Credit
- Earned when a task sleeps for a“long" time
- Spend when a task runs for a“long” time
- IC is used to provide hysteresis to avoid changing interactivity for temporary changes inbehavior
However,“interactive tasks” get special dispensation
To try to maintain interactivity
Placed back into active queue, unless some other task has been starved for too long…
Real-Time Tasks
Always preempt non-RT tasks
No dynamic adjustment of priorities
Scheduling schemes:
SCHED_FIFO: preempts other tasks, no timeslice limit
SCHED_RR: preempts normal tasks, RR scheduling amongst tasks of same priority
Choosing the Right Scheduler
| I Care about | Then Choose |
|---|---|
| CPU Throughput | FCFS |
| Average Response Time | SRTF Approximation |
| I/O Throughput | SRTF Approximation |
| Fairness(CPU Time) | Linux CFS |
| Fairness-Wait Time to Get CPU | Round Robin |
| Meeting Deadlines | EDF |
| Favoring Important Tasks | Priority |
Memory
Important Aspects of Memory Multiplexing
Protection:
Prevent access to private memory of other processes
Different pages of memory can be given special behavior (Read Only, lnvisible touser programs,etc).
Kernel data protected from User programs
Programs protected from themselves
Translation:
Ability to translate accesses from one address space (virtual) to a different one(physical)
When translation exists, processor uses virtual addresses, physical memory uses physical addresses
Side effects
Can be used to avoid overlap
Can be used to give uniform view of memory to programs
Controlled overlap:
Separate state of threads should not collide in physical memory. Obviously,unexpected overlap causes chaos!
Conversely, would like the ability to overlap when desired (for communication)
Binding of Instructions and Data to Memory
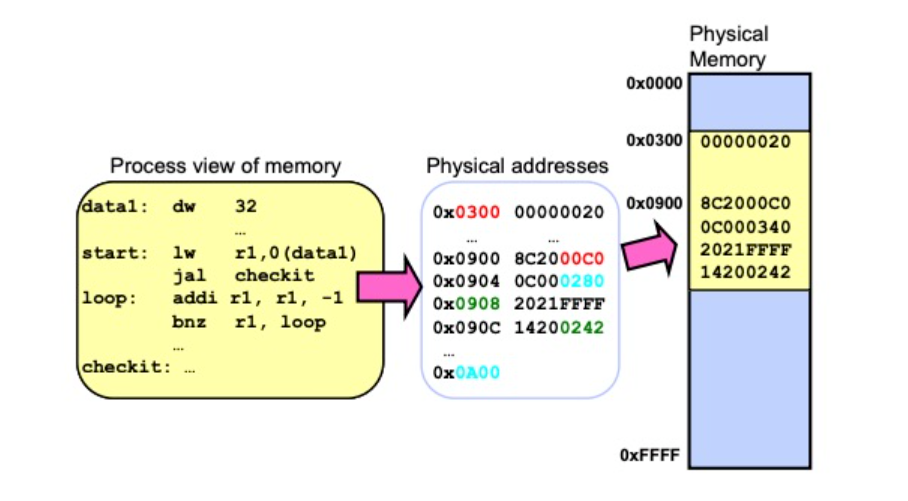
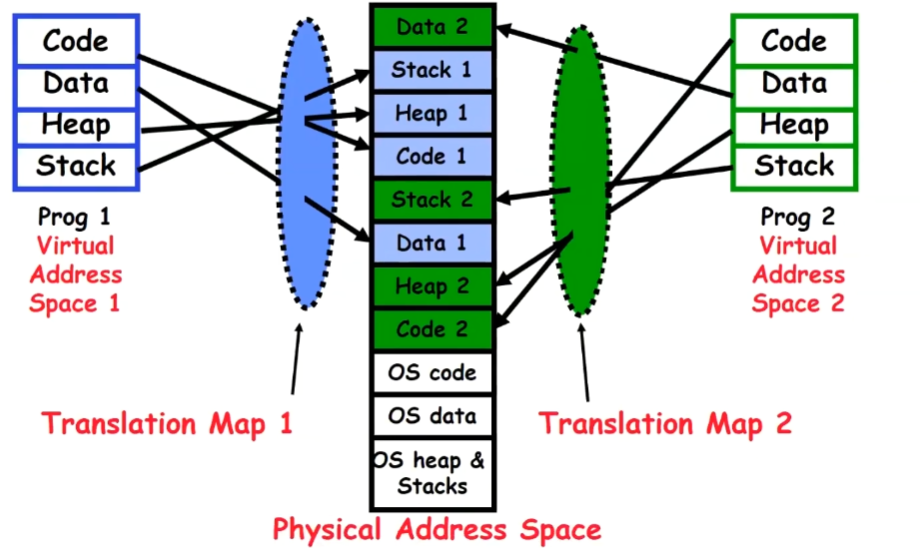
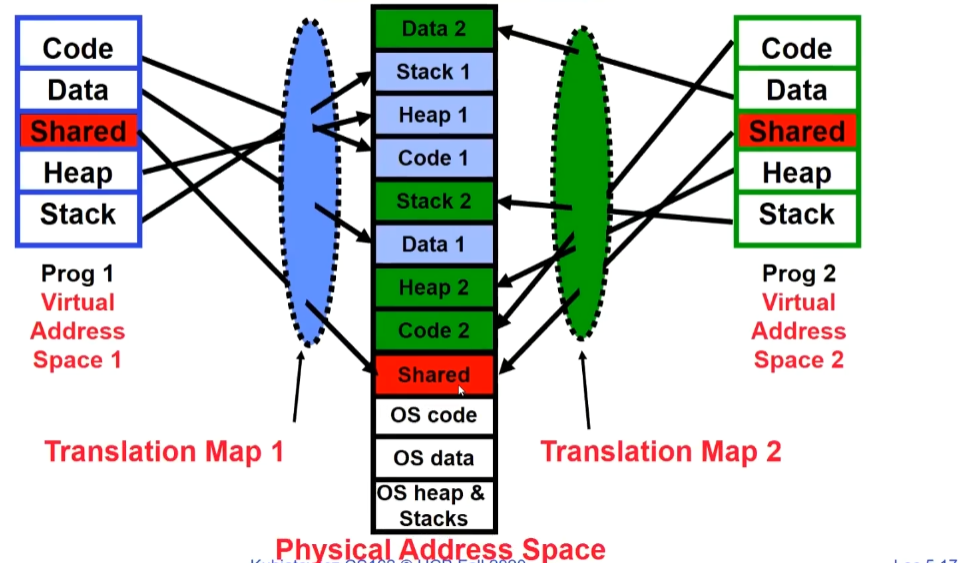
On the left side of the picture is the process perspective, where the process believes it has the entire memory block to itself. In the middle of the diagram is the indirection layer, responsible for translating the process’s virtual memory addresses into physical memory addresses. On the right side of the diagram is the physical memory space actually used by process A. At this point, a process B with the same program is launched. Similarly, after passing through the indirection layer, process B actually uses a different physical memory address, as shown in the picture below:
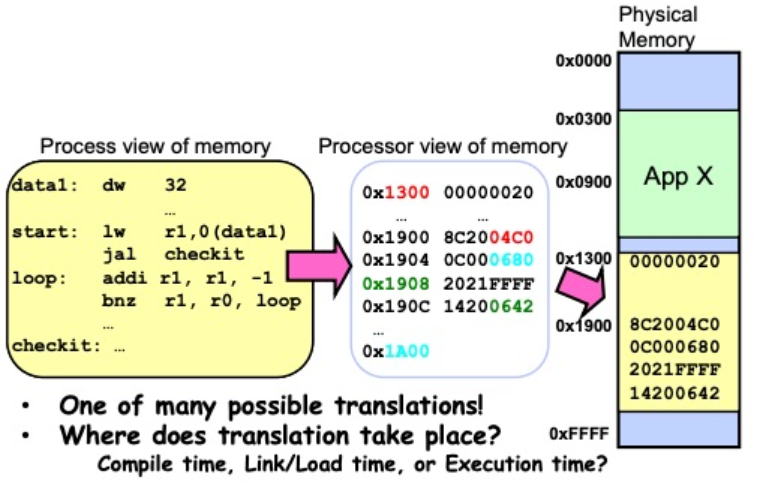
From Program to Process
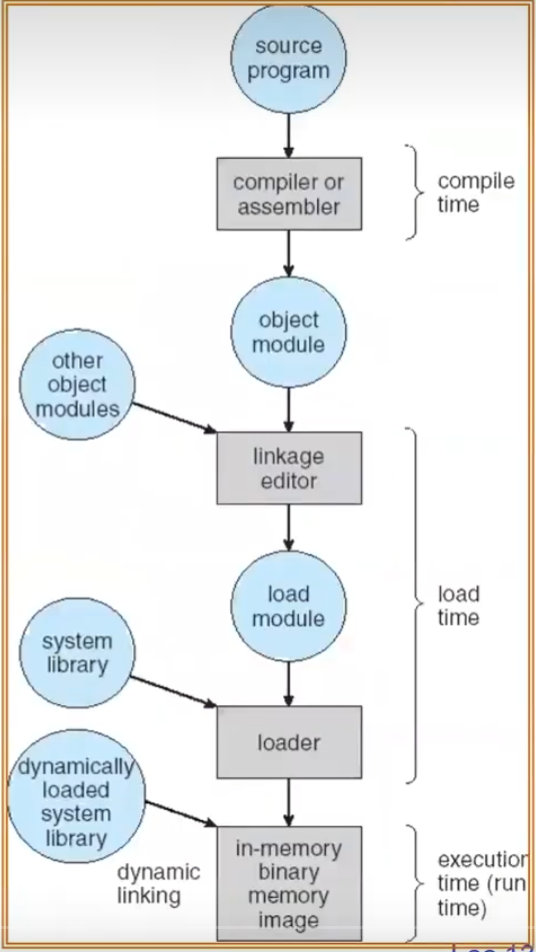
Preparation of a program for execution involvescomponents at:
Compile time (i.e.,“gcc”)
Link/Load time (UNIX“ld” does link)
Execution time (e.g, dynamic libs)
Addresses can be bound to final values anywhere in this path
Depends on hardware support
Also depends on operating system
Dynamic Libraries
Linking postponed until execution
Small piece of code (i.e. the stub),locates appropriate memory-resident library routine
Stub replaces itself with the address of the routineand executes routine
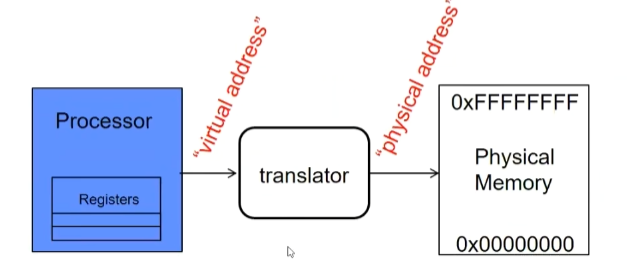
Address Translation
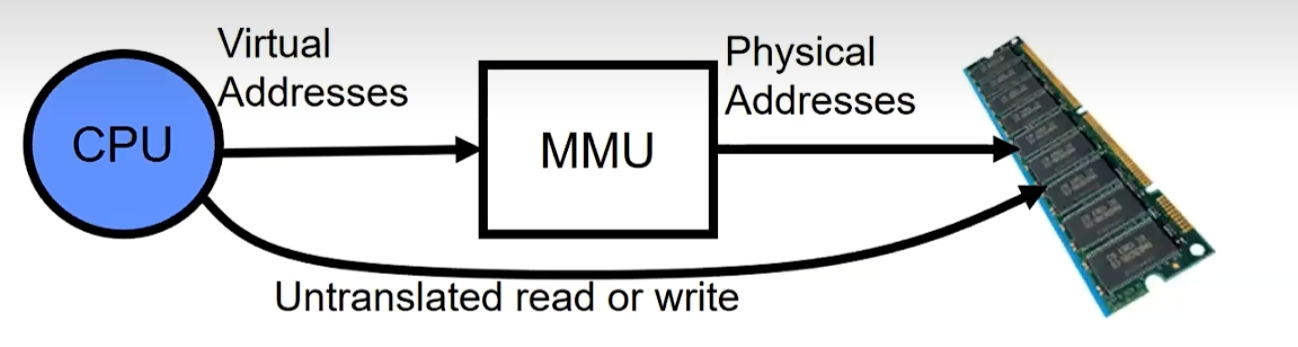
Consequently, two views of memory
View from the CPU (what program sees, virtual memory)
View from memory (physical memory)
Translation box (Memory Management Unit or MMU) converts between the twoviews
Translation => much easier to implement protection!
- If task A cannot even gain access to task B’s data, no way for A to adversely affect B
Issues with Simple B&B Method
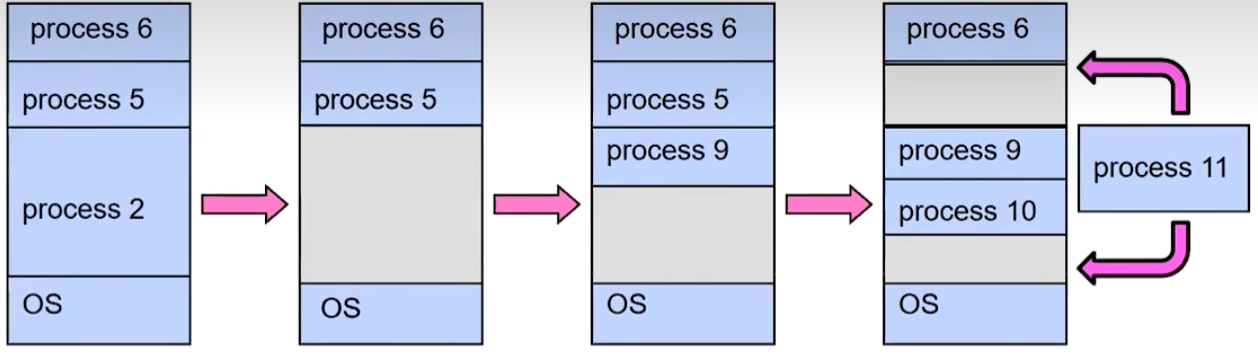
Fragmentation
Missing support for sparse address space
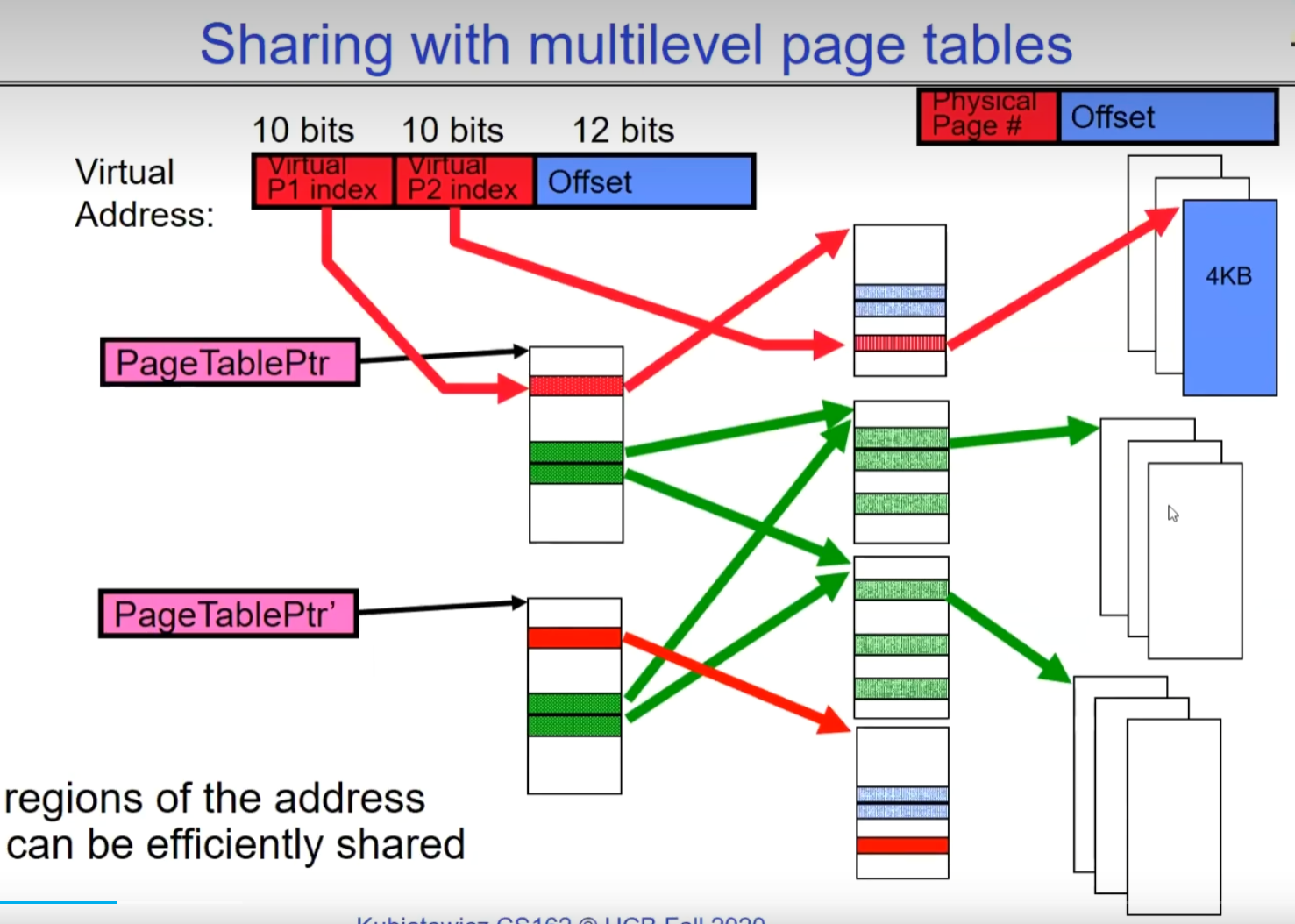
Inter-process Sharing
Multi-Segment
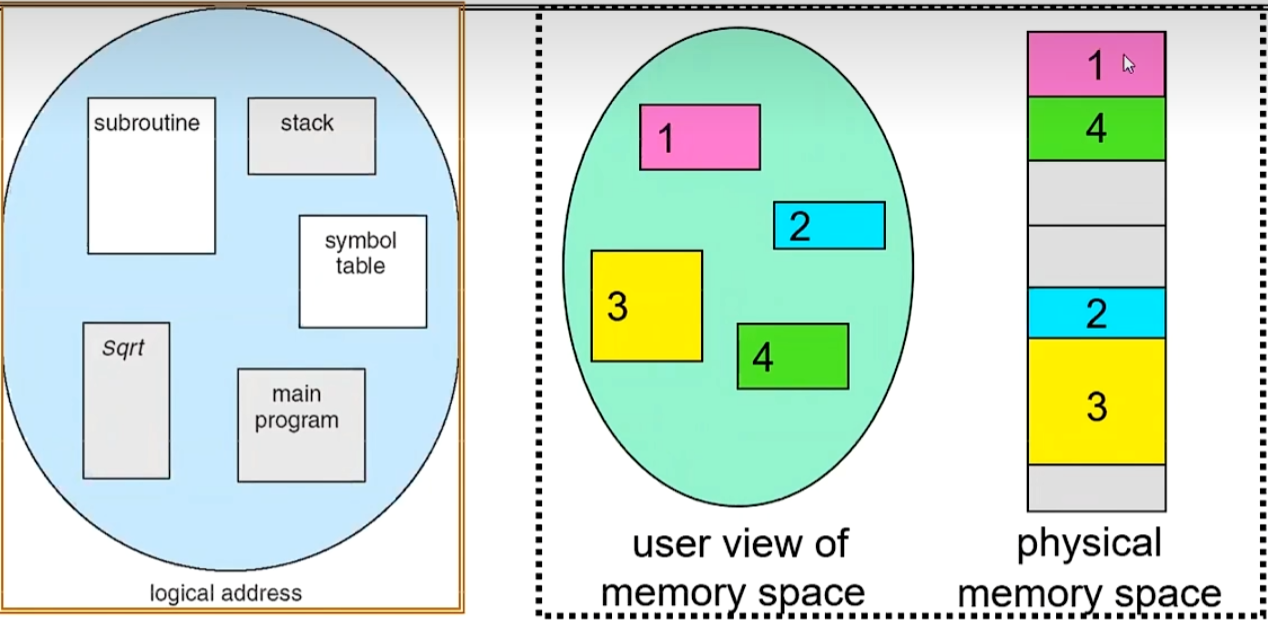
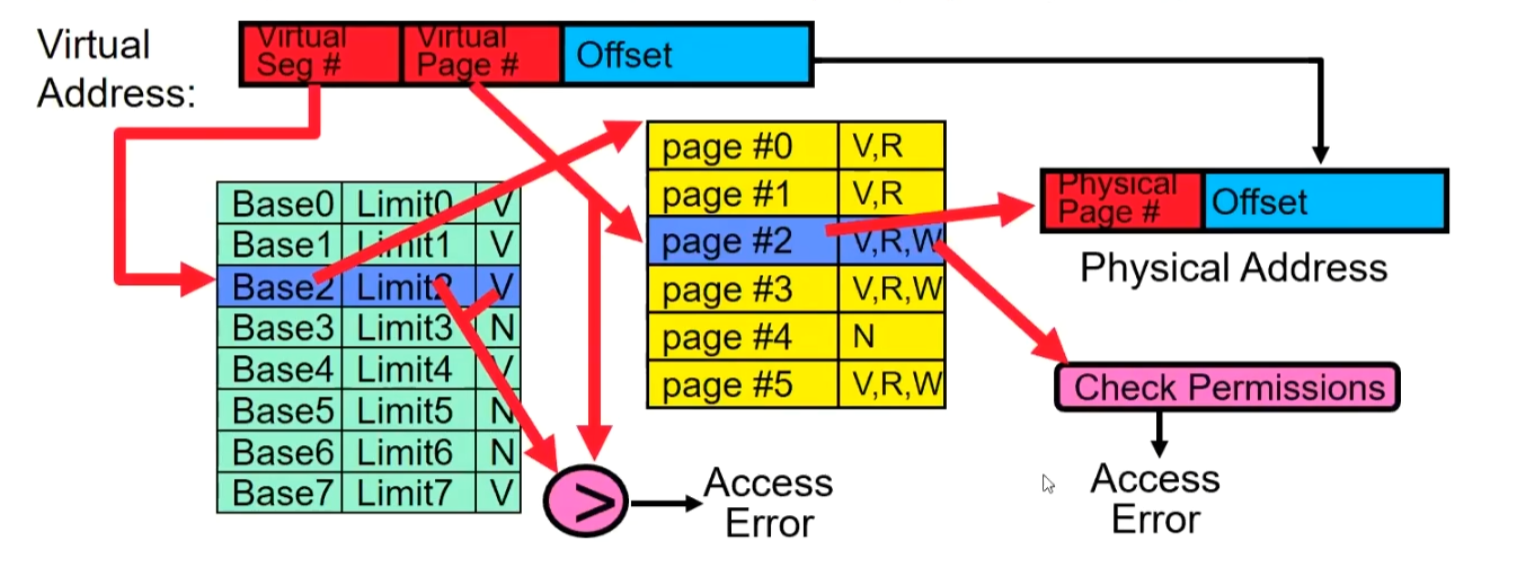
We can further divide a process into different segments, such as Code, Data, Stack, and so on. Each segment is assigned a Base and Bound, and can be allocated to any location in physical memory.
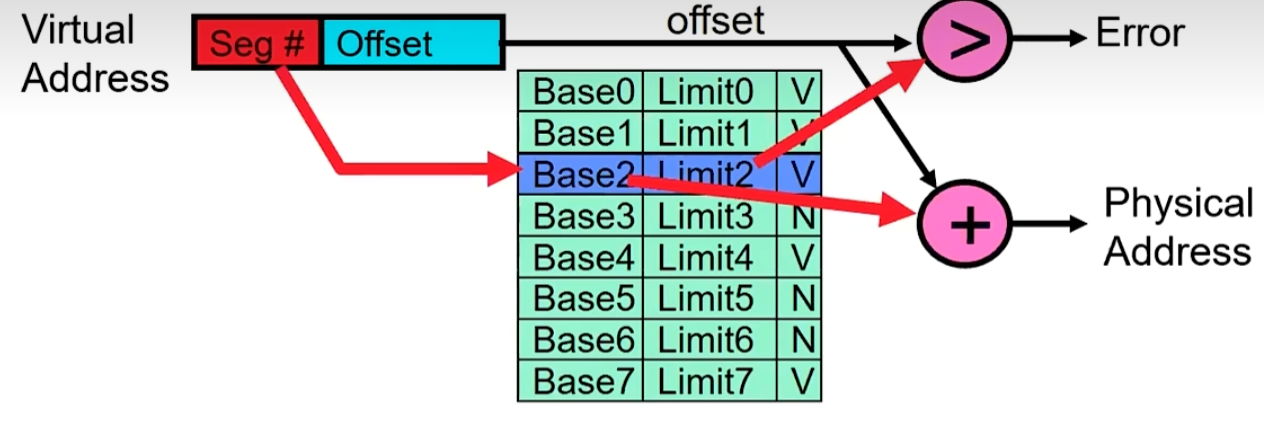
Segment map resides in processor
Segment number mapped into base/limit pair
Base added to offset to generate physical address
Error check catches offset out of range
As many chunks of physical memory as entries
- Segment addressed by portion of virtual address
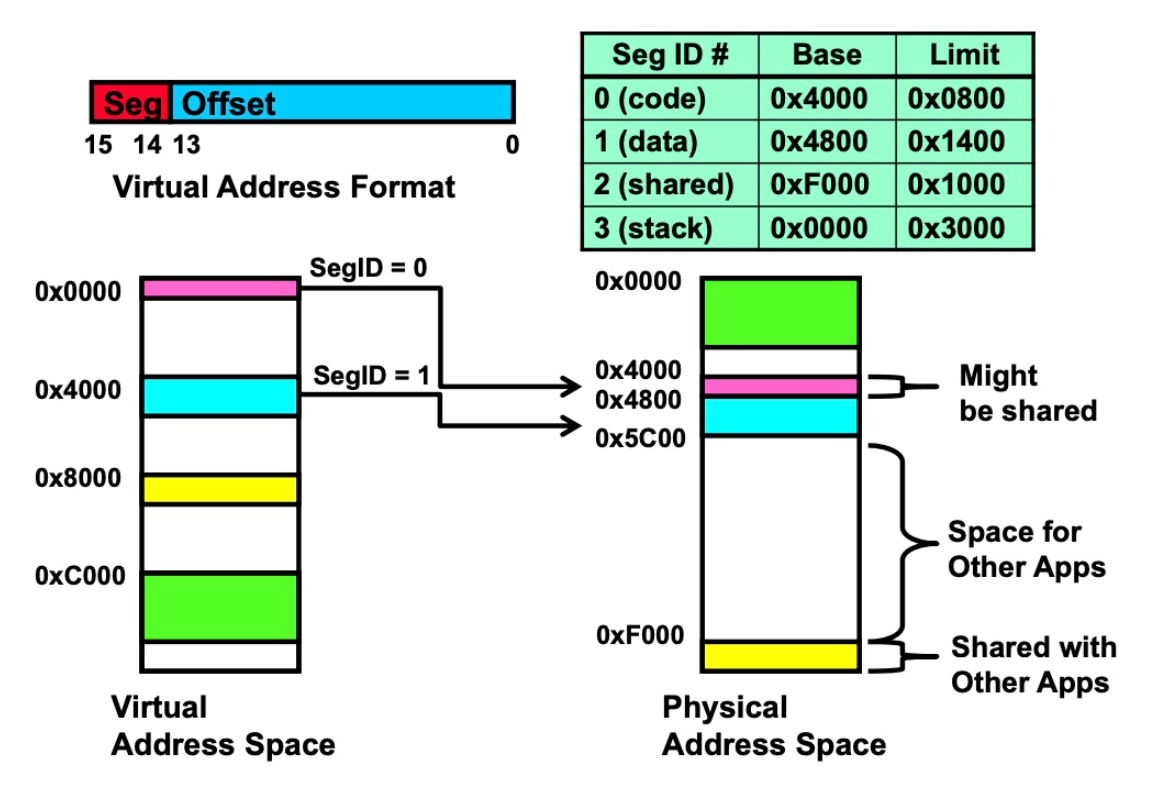
Summary of Multi-Segment’s disadvantage:
Different-sized segments must be accommodated in physical memory, potentially requiring complex placement strategies to fit more processes into memory.
High cost of swapping.
External/Internal Fragmentation.
Paging
The basic concept is to further divide physical memory into smaller, usually 1-16KB in size, equally-sized blocks known as pages. A bitmap is utilized to track the status (allocated/free) of each page. Correspondingly, the OS needs to maintain a page map/table for each process. This table contains information about the location of each page and relevant permission control details (V - valid, R - read, W - write), as illustrated in the diagram below:
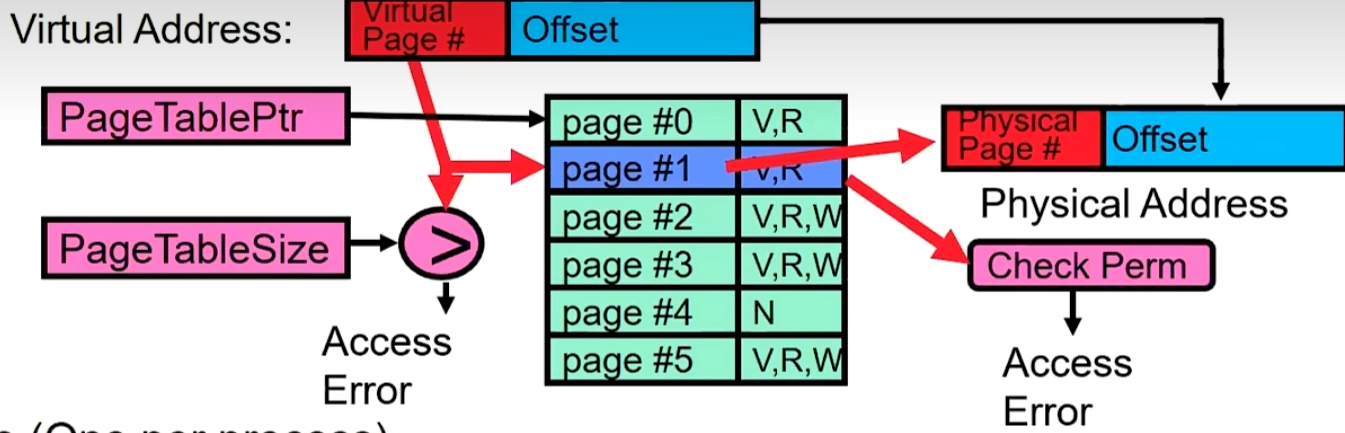
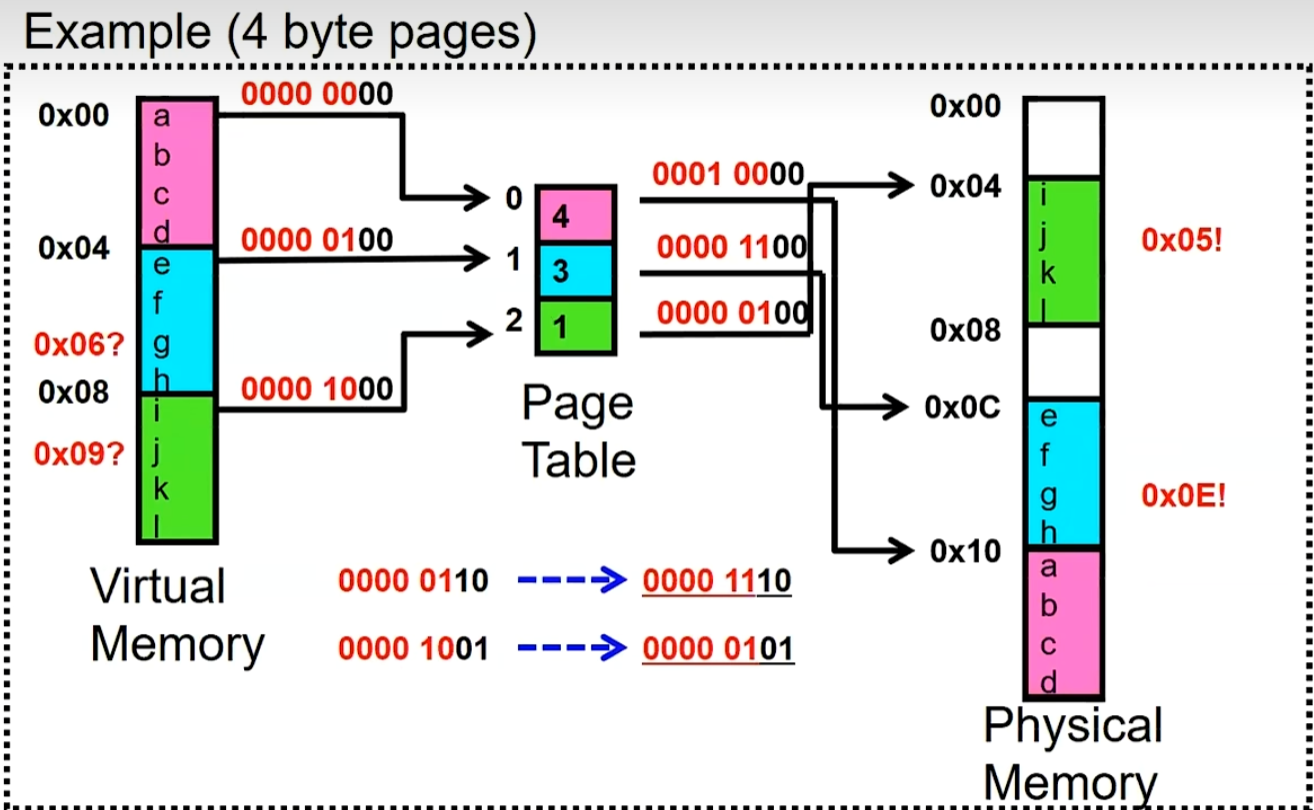
for example:
Pros & Cons of the paging strategy:
Pros:
Simple memory allocation.
Easy to share resources.
Cons:
- Address space is sparse. In a 32-bit system, assuming a page size of 1KB, each page table would be 2 million in size.
Two-level Paging
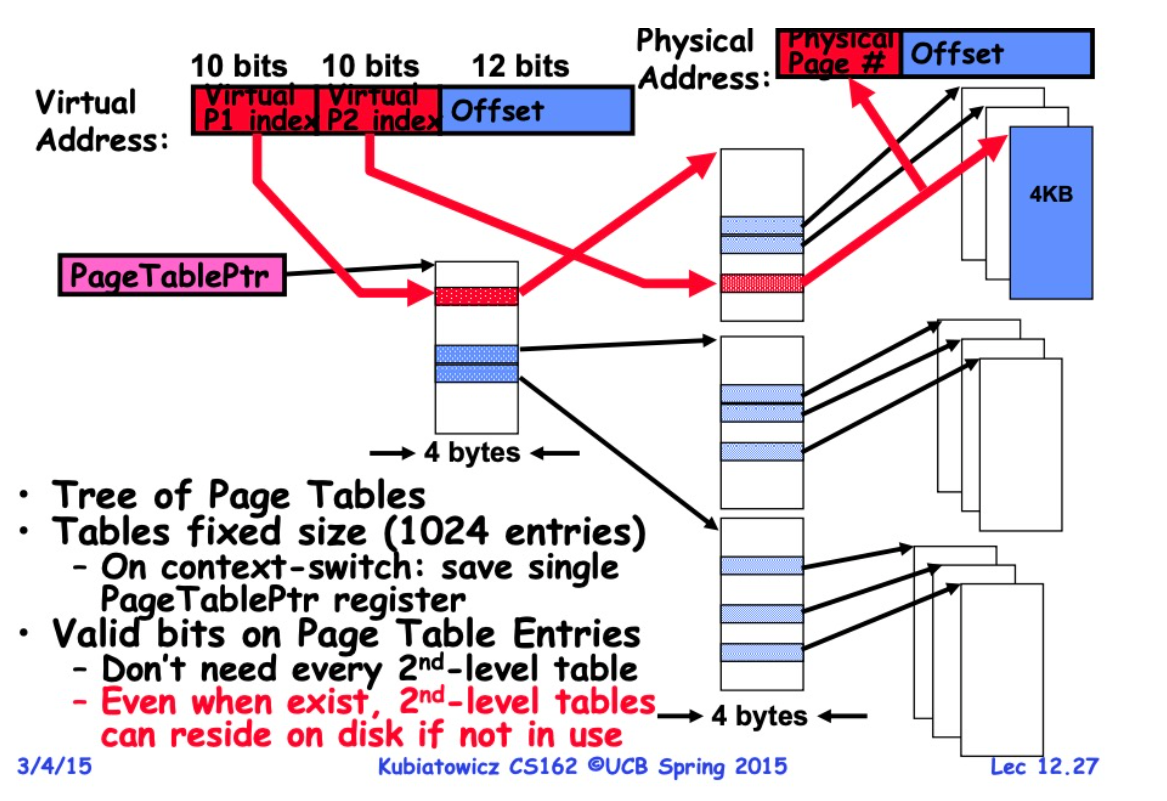
It can effectively save space.
Pros:
Compared to the Simple Page Table approach, the pageTable stored in memory is much smaller, conserving storage resources. Additionally, it allows utilizing demand paging to fetch secondary indices as needed.
During a context switch, only the pageTablePointer needs to be modified, rather than modifying the entire pageTable.
Cons:
- The cost of reading increases as it requires one or more reads of the page table before accessing the final data.
Segments + Pages
Demand Paging
Before a process begins execution, frequently used pages from the logical address space are placed in memory, while other pages require dynamic loading.
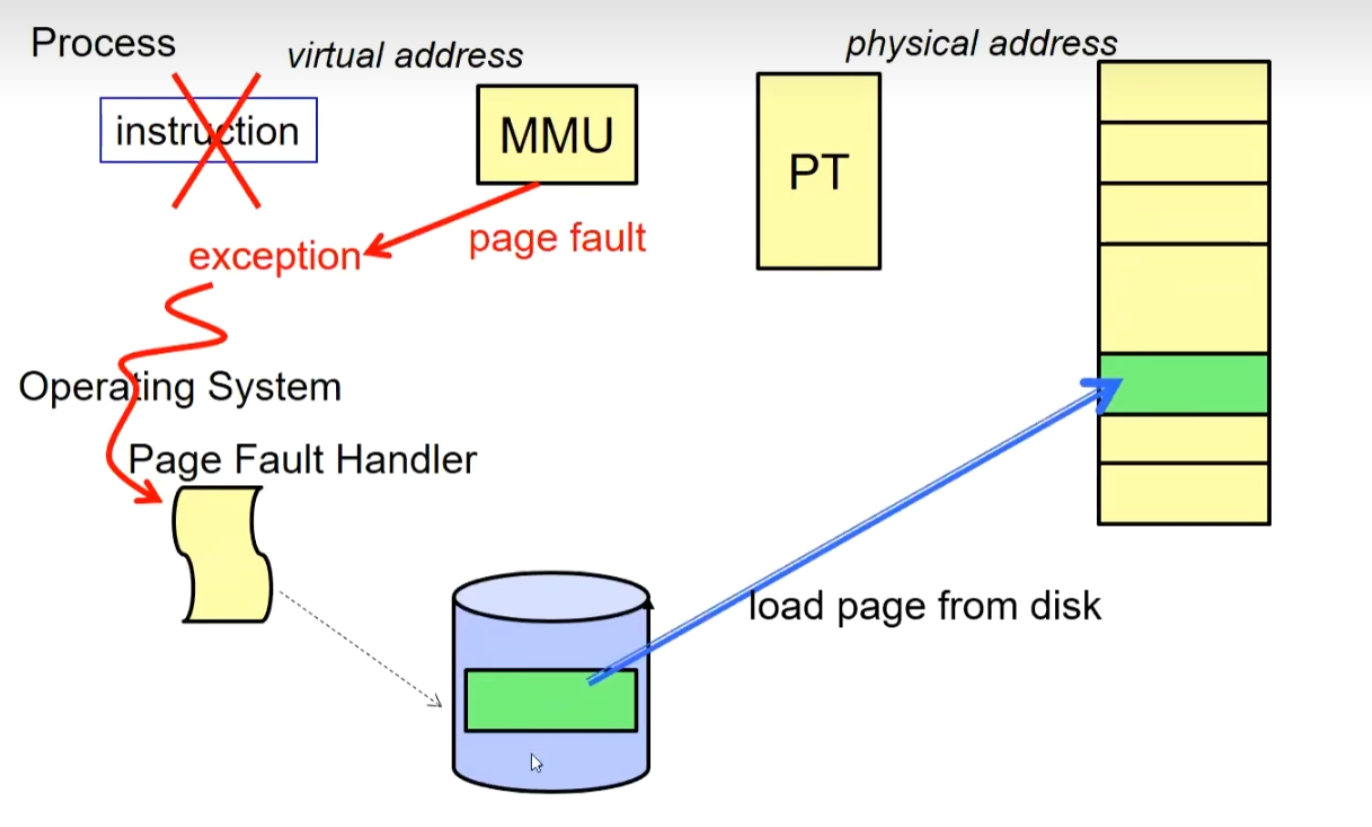
During execution, if a required page is not in memory, a page fault trap occurs, prompting the retrieval of the page from external storage into memory:
Choose an old page to replace
lf old page modified (“D=1”), write contents back to disk
Change its PTE and any cached TLB to be invalid
Load new page into memory from disk
Update page table entry, invalidate TLB for new entry
Continue thread from original faulting location
If placing the page into memory encounters no available free frame, a page replacement algorithm is employed.
Cost Model
Since Demand Paging like caching, can compute average access time!“Effective Access Time”)
EAT = Hit Rate x Hit Time + Miss Rate x Miss Time
EAT = Hit Time + Miss Rate x Miss Penalty
Page Replacement Policies
FIFO (First In, First Out)
Throw out oldest page. Be fair - let every page live in memory for same amount of time.
Bad - throws out heavily used pages instead of infrequently used
Having Belady’s Anomaly:adding some more physical memory and the fault rate goes up
RANDOM
Pick random page for every replacement
Typical solution for TLB’s. Simple hardware
Pretty unpredictable - makes it hard to make real-time guarantees
MIN (Minimum)
Replace page that won’t be used for the longest time
Great (provably optimal), but can’t really know future.
But past is a good predictor of the future…
LRU (Least Recently Used):
Replace page that hasn’t been used for the longest time
Programs have locality, so if something not used for a while.unlikely to be used in the near future.
Seems like LRU should be a good approximation to MIN
Approximating LRU: Clock Algoorithm
Clock Algorithm: Arrange physical pages in circle with single clock hand
Approximate LRU (approximation to approximation to MIN)
Replace an old page, not the oldest page
Details:
Hardware “use" bit per physical page :
Hardware sets use bit cn each reference
lf use bit isn’t set, means not referenced in a long time
Some hardware sets use bit in the TLB; must be copied back to page TLB entry gets replaced
On page fault:
Advance clock hand (not real time)
Check use bit: 1–used recent; clear and leave alone 0–selected candidate for replacement
How is translation accomplished?
Hardware Tree Traversal:
For each virtual address, traverse the page table in hardware.
If an invalid Page Table Entry (PTE) is encountered, trigger a “Page Fault,” and the Fault handler initiates subsequent page retrieval operations.
Pros: Fast
Cons: Less flexible at the hardware level
Software Tree Traversal:
Perform the mentioned traversal in software.
Pros: Flexible
Cons: Slower